Releasing the CAPTCHA Cracken
By Sean Brodie on 20 May, 2020
Introduction
In January 2019 we released a blog post talking about how text-based CAPTCHAs can be cracked using machine learning. Over the last year, we have been surveying the threat landscape and cracking all of the CAPTCHAs we found. We even built a CAPTCHA cracking server, fondly named CAPTCHA22, in order to speed up the cracking process and create a safe place to store CAPTCHAs.
If you want to jump straight to the tool and rummage in the source, you can find it here.
The usual routine for the last year was:
1. We find a CAPTCHA on a test.
2. We log a CAPTCHA cracking request.
3. We label roughly 200 CAPTCHAs and feed them to CAPTCHA22.
4. CAPTCHA22 provides results on how many were cracked (usually above 80% accuracy).
Life was good.
However, a while ago a bit of a more interesting request came across our desk. Our red team requested that we assist them in cracking a CAPTCHA that was sitting in front of an Outlook Web App (OWA) portal. The idea was that if we could reliably crack it and automate the process, the red team would simply be able to plug in their normal enumeration scripts required to perform the attack simulation. In addition, it is typical to not allow lockout of accounts on OWA portals, thereby relying almost solely on a CAPTCHA to ward off automated attacks.
So the hunt begins. Strap in and prepare for a journey of high grade AppSec hackery!
Cracking the CAPTCHA
Following the same principles as discussed in the previous blog post, the CAPTCHA cracking process started with manually labelling CAPTCHAs. Based on previous experience, we were pretty sure that this would be an easy CAPTCHA to crack. So it came as a massive surprise when Captcha22 gave us the following initial results:

That was unexpected? Although the noise in the CAPTCHA was significant (see the one letter below, for confidentiality reasons we can't show the full CAPTCHA), we did not think it would be this bad?
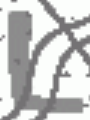
So back to the drawing board. We decided to increase our labelling efforts and ramp up from the usual 200 labelled CAPTCHAs to roughly 1400. What was also interesting, and served to further confuse and frustrate us based on the bad results we were achieving, was the fact that we were getting repeated CAPTCHAs. Comparing the digests of the CAPTCHAs indicated that roughly 5% of all CAPTCHAs were repeated. Even more frustration came with the new results, why was CAPTCHA22 failing this hard?

After some late night debugging, we figured out that the sneaky CAPTCHA had different image-to-text ratios than any of those we had previously cracked. The hard coded defaults were not providing a big enough sliding-window for the CNN to use the full character for recognition. The window is calculated as a percentage of the width of the CAPTCHA. As this CAPTCHA was quite stretched out, the window percentage had to be adjusted accordingly.
While we were at it, we decided to do something about the noise levels. A closer inspection indicated that the greyscale value of noise and text was always within two distinct and constant ranges. A quick OpenCV conversion to greyscale and a NumPy histogram function allowed us to filter out the noise and produce clearer characters like the one shown below.
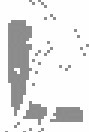
We also realised that some of the CAPTCHAs were labelled incorrectly due to human error. Was that an I or l? Y or V? A few quick tests on the online CAPTCHA system gave us hope by showing that "I" was never the answer. We could therefore restrict our alphabet.
Turns out we labelled roughly 50 CAPTCHAs incorrectly for every 300 labelled. Some quick fixes and the joining all of all of these lessons and finally, the CAPTCHA started to buckle.

At this point we had sufficient accuracy to move on to the submission phase. The general flow of the CAPTCHA cracking system was:
1. Load the OWA page and extract the CAPTCHA (Python requests libs FTW)
2. Filter the noise out of the CAPTCHA
3. Compare the digest of the CAPTCHA to those previously seen. If found, submit that answer, else continue
4. Submit the CAPTCHA to CAPTCHA22 via its API and request recognition to be performed
5. Receive the CAPTCHA answer from CAPTCHA22
6. Submit to the page
7. If we are redirected to the OWA login page, store the CAPTCHA in the correct folder; if not, store it in a separate folder for manual correction
8. Retrain the CAPTCHA cracking model with the newly saved CAPTCHAs to improve accuracy in the long run
We always thought CAPTCHA cracking was the hard part. Who knew submitting to the page would have us stumped?
All is not what it seems
While one consultant was furiously labelling CAPTCHAs, another was looking for the CAPTCHA submission request so that it could be mimicked with the python requests library's session class. One full hour later and that request was nowhere to be found.
It seemed that the CAPTCHA POST request was non-existent. Instead, the CAPTCHA was sent as a value appended to a cookie. Even in incognito mode, these cookies didn't exist until just before the CAPTCHA was submitted.
Turns out it was all JavaScript. This CAPTCHA was so hardcore that it used JS to keylog the user as they typed the answer to the CAPTCHA. Each keystroke was then sent into the abyss of over 160 obsfuscated and minified JS functions to generate three 128 byte strings, using some enigma-level code. These values were then added via JS as cookies and the CAPTCHA answer appended to two of the three cookies. The website then performed a refresh on itself and if the cookies and CAPTCHA were correct, the OWA login portal appeared. Mess with the cookies or get one out of the 128 bytes wrong in any of the three cookies, the server would take you to a static page stating that you are not a human.
How dare they question our humanity! To make things worse, after ten seconds of tomfoolery on the OWA login page, you would be requested to fill in a CAPTCHA again, even when doing things manually. These guys were really discriminating against robots. Back to the drawing board.
Becoming Pyppeteer Pirates
We could try to painstakingly reverse engineer the 160+ JS functions. But where's the fun in that? Cue Pyppeteer.
Pyppeteer is the unofficial port of Puppeteer to Python, that allows you simulate a browser and inject commands via a very convoluted pipeline between Python, JS, and Chromium. The idea was to automate the interactions with the browser window, go to the OWA page, extract the CAPTCHA for CAPTCHA22 to solve, then simulate the keystrokes a user would perform to type in the CAPTCHA, forcing the obsfuscated JS to generate the cookies for us.
Pyppeteer could also detect whether the OWA login page or CAPTCHA wall was showing and alter its behaviour accordingly. The idea was that on the CAPTCHA wall, the script would interface with CAPTCHA22 to bypass the wall, then run whichever script it was provided by the red team. If the wall came back up, the script would remember it's last position and continue as soon as CAPTCHA22 was able to submit a successful CAPTCHA response. Pyppeteer would also provide CAPTCHA22 feedback on how accurate the submissions were to help it train itself. The fully automated and final pipeline of what is now called CAPTCHA Cracken is shown below.
Knocking on OWA's door
One and a half days after the request came across our desk (talk about a good turnaround time), we were ready.
What's next?
We said it last year and we will say it again: text-based CAPTCHAs are just not cutting it anymore. Unless you use a third-party like reCaptcha, you just can't prevent automated attacks with a CAPTCHA anymore. Even then safety is not guaranteed! There are some interesting new CAPTCHA samples on the market, but it is just a matter of time before these also buckle under the CAPTCHA Cracken. We are not saying that CAPTCHAs are useless, they should just not be seen as the silver bullet that stops automated attacks.
You have to accept that automated attacks are a thing. You need to take a holistic view of your authentication system. You can't give away half the login information with username enumeration. Weak passwords and bad password behaviours are not going away and are almost trivial to exploit. Sucks for usability, but accounts have to be locked after a certain number of incorrect attempts. MFA for anything remotely sensitive is an absolute must.
The robot revolution is here, who knew it would come with human puppet strings?