CAPTCHA-22: Breaking Text-Based CAPTCHAs with Machine Learning
on 17 January, 2019
Overview
We’ve all been there before. You’re looking at a simple CAPTCHA and you think to yourself, I can crack that. Maybe it’s a dead-simple picture of some slanted text, maybe it has a couple of lines through it or maybe some of the words are a bit wobbly. You don’t have time to waste fiddling with OCR, but you have the strong sense that this CAPTCHA is trivially bypassable with modern technology.
The following examples show CAPTCHAs that could be trivially solved using minimal pre-processing techniques and a standard pre-trained OCR model:


A CAPTCHA (Completely Automated Public Turing test to tell Computers and Humans Apart) is a challenge-response problem that, if correctly implemented, can only be solved by a human. Since originally being developed in 2003, the use of CAPTCHAs has grown steadily. They are primarily used in locations where sensitive information is required or revealed, such as authentication or registration processes. The primary goal of a CAPTCHA is to prevent automated attacks such as spam, username enumeration and password brute-forcing. If only a human can solve the challenge, it becomes impossible to create automated scripts to brute-force the mechanism or enumerate sensitive information from it.
CAPTCHAs come in many forms, ranging from third party solutions, notably Google’s reCAPTCHA, to custom implementations. The emphasis of this post was to evaluate text-based CAPTCHAs, which require a user to enter text for a given image. As existing solutions often come with a cost, internally developed text-based CAPTCHAs are a frequent sight. As with most security controls, reinventing the wheel comes with its own set of problems.
You can have the strongest, most complex CAPTCHA, but this means nothing if it is not implemented correctly. Common mistakes we see in the field are hardcoded developer bypasses, disclosure of the CAPTCHA’s answer in server responses, and even complete failure to validate the CAPTCHA (i.e. a fail-open).
But if you’re able to avoid these mistakes, and make use of sufficiently complex text-based images, you might feel pretty confident that it would block automated attacks.
However, with the rise in machine learning techniques and computational power, even well-implemented text-based CAPTCHAs should be considered vulnerable. Powerful character-recognition technology is no longer limited to academics and Google. Below, we demonstrate how six custom-implemented test-based CAPTCHAs were cracked with freely available open-source software.
How We Got Here
Attempting to crack CAPTCHAs is a task that forms part of common web application security testing methodologies. The traditional approach to this has been to sanitize the CAPTCHA with image pre-processing techniques, and then attempt to solve it using an existing OCR model. But this can require a lot of manual tweaking, and because assessments generally have strict time constraints and applications generally have more critical functionality to test than their CAPTCHA, developing an effective CAPTCHA cracker is usually impractical.
We attempted the traditional approach against what appeared to be a fairly simplistic CAPTCHA. The images in this CAPTCHA had minimal noise, and the character set was fairly restricted. While the characters were three dimensional, this effect could be filtered out, as the effect was a different color to the base character outline. Feeling confident, we pulled 500 CAPTCHAs and decided to test our theory.
We tried various pre-processing techniques to sanitize the images for the Tesseract-OCR model. To our dismay, it would fail every single time. If we were lucky, the OCR would correctly guess two out of the five characters. No matter what filtering techniques we tried, nothing got us near levels of accuracy that would pose an actual threat.
After spending a couple of hours on this, we decided that maybe we were looking at this problem from the wrong angle. Why are we trying to sanitize the CAPTCHA to have it fit an already-trained OCR model? Why can’t we train an individual model for this specific CAPTCHA?
A quick Google search provided the ideal Tensorflow model that could be trained for OCR: Attention-based OCR (AOCR). Training a model requires both training and validation data. Taking two hours, we set out to manually label all 500 CAPTCHAs. We fed the model 450 CAPTCHAs for training, thus leaving 50 for validation. Training on the laptop CPU took roughly an hour. Still not really optimistic, after the laborious process of labelling the data and a full day of trial and error, we decided to stop training and run the validation data.
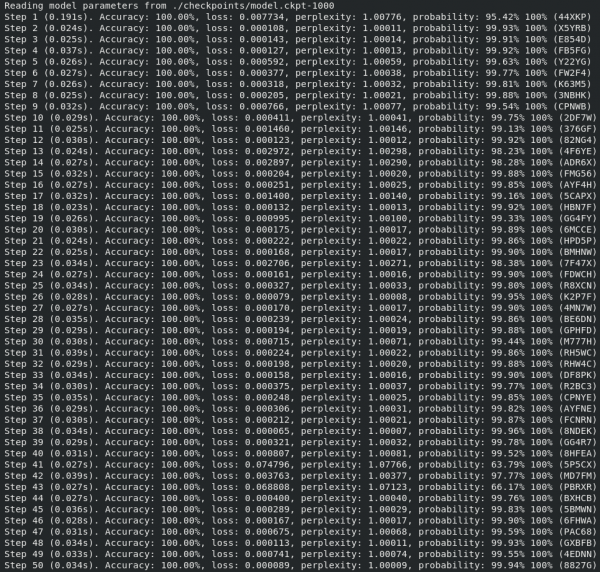
We had to run it three times – we really didn’t believe the results. 100% accuracy. Not a single mistake was made.
As the model trained, it kept a measurement of the accuracy and the probability of confidence in the solution. Interestingly, analysis of this metric indicated that we had made labelling mistakes in the initial dataset. In four instances, we had labelled an “M” as an “N”, and this was detected by the trained model.
Doubting the statistical significance of our results, we knew we needed a larger sample size. So, after the celebrations, we upped the model to 1500 CAPTCHAs: 1000 for training and 500 for validation. Again, we were able to achieve a 100% accuracy rate.
The Training Process
For a detailed how-to guide on the process and scripts to aid in creating your own CAPTCHA cracking machine, refer to this Github repo.
To train a learning model, a significant sample set of CAPTCHAs must be retrieved. The process of collecting a dataset can be automated to retrieve a large sample set in a relatively short time, e.g. by purposefully submitting incorrect usernames and saving the generated CAPTCHA.
For some of the more simple CAPTCHAs, we discovered that 500 labelled data points were sufficient to provide positive results, while more complex ones required over 1000. In instances where we struggled with the manual classification process, more samples were required to provide accurate results.
The second step required the dataset to be manually labeled. Depending on the complexity of the CAPTCHA, the ease of this step can vary. The monotony of this step does not.
The labelling process was streamlined as much as possible with a script. The CAPTCHAs were displayed one at a time for labelling, using OpenCV, after which the image was saved with the label as the file name. To put the human effort required into perspective, labelling took an average of one hour per 1000 CAPTCHAs.
The Attention-based OCR (AOCR) model was used for classification. This Tensorflow OCR model, developed by Qi Guo and Yuntian Deng, uses a sliding convolutional neural network (CNN) stacked with Long Short-Term Memory (LSTM) units for classification. These are all big and complex AI terms that we will not discuss here. What we want to show is how, through a quick Google search and by following a Github README page, almost anyone with basic development skills could start cracking CAPTCHAs.
To further prove the point, initial training was done on a Core i7 workstation laptop with Tensorflow running on the CPU. With this method, each training step took an average of 2.5 seconds. For most examples, anywhere between 1000 and 2000 steps were required. The largest models would train in under two hours.
As an experiment, a GPU-enabled Tensorflow build was tested on an Nvidia GTX 960. The average training step time fell to 0.2 seconds. As mentioned previously, training a model for more complicated CAPTCHAs requires more training steps and time. Should the complexity and number of steps substantially increase, switching to training on a GPU could provide a significant performance upgrade.
Results
In the interests of space, a description of each CAPTCHA and its various complexity factors are included in the table below.
| CAPTCHA # | Background Noise | Foreground Noise | Character Color Randomization | Character Distortion | Character Set |
| C-1 | None | Shadows on the letters | One of two monochromatic colors | Minimal character size and rotational distortion | A-Z, 0-9, excluding easily confused character |
| C-2 | Random monochrome color | Lines and dots over characters | Random monochrome colors | Significant character size and rotational distortion | A-Z, a-z |
| C-3 | Constant white to red gradient | None | Random monochrome colors | Minimal character size and rotational distortion | A-Z, 0-9, excluding easily confused characters |
| C-4 | Monochromatic background character | Moving letters | Random monochrome color matching the background | Minimal character size and rotational distortion, significant letter overlapping | A-Z, 0-9 |
| C-5 | Significant Gaussian noise | Significant Gaussian noise | Single monochrome color | Minimal character size distortion, significant rotational distortion | a-z |
| C-6 | Moderate Gaussian noise and shades of grey | Random lines and minimal Gaussian noise | Shades of grey | Minimal character size and rotational distortion, occasional cropping of letters | a-z, 0-9 |
The accuracy results for each of the CAPTCHA models is shown below:
| CAPTCHA # | Correct | 1 Incorrect Character | 2 Incorrect Characters | More than 2 Incorrect Characters |
| C-1 | 100% | 0% | 0% | 0% |
| C-2 | 35% | 40% | 15% | 9% |
| C-3 | 79% | 14% | 6% | 1% |
| C-4 | 15% | 29% | 35% | 21% |
| C-5 | 8% | 27% | 31% | 33% |
| C-6 | 53% | 36% | 9% | 3% |
Although at first glance the results for all CAPTCHA might not look very impressive, the next table proves otherwise. As mentioned, the model will output the CAPTCHA predictions as well as a certainty measurement that the prediction is correct. Correct guesses typically have a higher certainty than incorrect guesses. A minimum certainty value or threshold can thus be specified. If the received CAPTCHA prediction’s certainty does not exceed this threshold, a new CAPTCHA will be requested. This approach will limit submissions of potentially incorrect CAPTCHA values, but at the cost of discarding some CAPTCHAs. The higher the threshold, the more CAPTCHAs will be discarded.
The trade-off between certainty thresholds and discarded CAPTCHAs is shown in the table below. The values for each CAPTCHA indicate how many CAPTCHAs will be discarded on average to submit one CAPTCHA, if we want to achieve the specified acceptance rate.
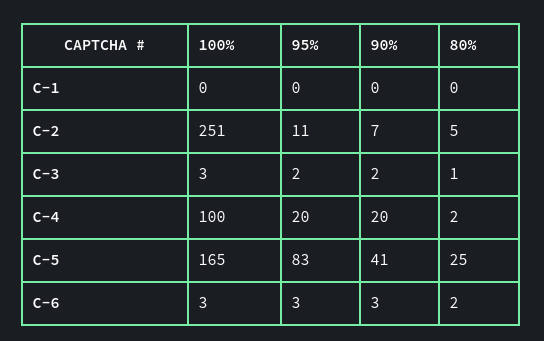
Consider C-2: if we want to submit CAPTCHAs to the server knowing that close to 100% of all submissions will be correct, our filter would only allow 1 out of every 250 CAPTCHAs to be submitted. If we lowered our acceptance rate, accepting that roughly 10% of all submissions would be incorrect, one out of every eight CAPTCHAs would be allowed by the filter. In contrast, for C-1, since no errors were made in the prediction, no CAPTCHAs would have to be discarded to achieve any acceptance rate.
Complexity vs. Human Friendliness
As seen in the results above, the obvious solution to this problem is to make text-based CAPTCHAs more complex, e.g. add more noise, cluster text, and increase length and the available character set. The following example could be considered as a more secure implementation of a text-based CAPTCHA:

Naturally, solutions come with the trade-off between usability and human friendliness. If a trained model achieves 50% accuracy on a CAPTCHA, but humans on average mimic the same results, is the model really flawed? The goal of a successful automated solution is not necessarily to achieve a 100% success rate, but rather to achieve a human-like degree of accuracy. If a model can achieve human-level accuracy, noise generated from incorrect CAPTCHA submissions will be masked as normal human error.
As mentioned previously, the AOCR trained model provides not only a classification for the CAPTCHA, but also a probability that the prediction is correct. This value could be used in difficult cases to ensure high levels of prediction accuracy by discarding classifications that are below a certain prediction probability, and then requesting a different CAPTCHA.
What’s Next?
This is not a new problem. In 2014, it was already shown that techniques are available to crack text-based CAPTCHAs through automated means. We have only shown how four years of progress have significantly reduced the effort required to break these systems.
While this post aimed to highlight the insecure nature of text-based CAPTCHAs, different types of third-party CAPTCHA solutions exist which can be more complex for computers, but still usable by humans. A popular CAPTCHA implementation is Google’s reCAPTCHA. reCAPTCHA is a image-based CAPTCHA that requires users to click all the images that match a provided description. Although the image-verification challenge itself is considered more secure, it has been proven that the challenge can be bypassed by requesting and automatically solving the audio challenge instead. Additionally, much like text-based solutions, it’s only a matter of time before computational power also trivializes this approach.
Another such solution that is gaining traction is to build a threat model based on the user’s behaviour. For example, humans would move their mouse in non-linear paths, would have inconsistent click rates and would scroll to read content. One such example is Google’s reCAPTCHA v3. Currently, this would still entail integrating third-party components, but it does seem to be the best solution.
The use of third-party solutions does come with a limitation, as businesses may not always be willing to implement third-party software into sensitive applications. As it stands now, developers at organizations unwilling to join the Google revolution can only attempt to make CAPTCHAs sufficiently complex while we wait for a better solution.
The goal of a CAPTCHA is to block spam and automation by requiring interaction from a human user. As AI grows in capability and sophistication, this is becoming a more difficult task. This emphasizes the importance of defense in depth. Should the line of defense provided by a CAPTCHA within login functionality fail, accounts can be further protected against brute-force automated login attempts through features such as an account lockout policy, a strong password policy, and two-factor authentication. As the effort required to break CAPTCHA solutions decreases, automated enumeration and other brute-force attacks will become more viable, and this should be factored into mitigation strategies.