Cat-Scale Linux Incident Response Collection

On 30 September 2019, Joani Green and John Rogers gave a talk titled "Performing Linux Investigations at Scale" at the SANS DFIR Summit in Prague. This talk was based on the early versions of the Open-Source F-Secure Linux Cat-Scale collection script. Cat-Scale stands for "Compromise Assessments at Scale" and was developed during several incident response and compromise assessment engagements to collect forensic artefacts from various Linux environments. A Logstash configuration was also developed for the output to parse the data into an ELK(Elastic-Logstash-Kibana) stack to allow analysts to query and aggregate the data efficiently.
Over the years, we have been actively using this script to help clients investigate, contain, and remediate incidents of all sizes. Naturally, Cat-Scale had to also evolve to match the threat landscape and to accommodate ever changing networks.
However, apart from the talk given by Joani and John, we had not had the opportunity to introduce Cat-Scale formally. In this blog post we would like to discuss Cat-Scale, it's capabilities and provide guidance on how you can best leverage it.
Problem
The usage of Linux operating systems has been gradually increasing over the years with organisations transitioning to cloud, Linux incident response tooling and research still lacks the development it requires. While many tools and frameworks both open-source and commercial exists to collect and parse Windows artefacts at scale, few options are available for Linux systems. Furthermore, majority of EDR solutions does not provide support for older versions which you are bound to come across during an incident response engagement.
While Cat-Scale could be used against simply one host, it aims to answer the question of "How does one collect and analyse data across 100+ Linux hosts?".
Introducing Linux Cat-Scale
GitHub Repository: https://github.com/FSecureLABS/LinuxCatScale
F-Secure Linux Cat-Scale script is a bash script that uses native binaries to collect data from Linux based hosts. While some of the data is captured from the console outputs of the tools, the rest are archived in their original form. The data is collected in order of volatility to ensure volatile data is captured in its purest form. Once the data is collected, analysts can review the output as text files or utilise an ELK deployment to ingest the data using the Logstash configuration provided. This allows analysts to hunt for indicators of compromise across multiple hosts which are not covered by EDR or to follow up on suspicious activity which has been detected by other means.
It should be noted that while Cat-Scale may provide an extensive list of artefacts, the main purpose of the tool is to provide DFIR professionals with triage output at scale to determine the extent of a breach, and to determine if a given host has been compromised.
The output of Cat-Scale may very well answer most of the questions you have about the compromise. The tool is not a substitute for forensic acquisitions, but rather a tool to support triage. It should be noted that live triage tooling would leave its own artifacts . This should be considered before execution. The tool is not a substitute for forensic acquisitions, but rather a tool to support initial triage and assist in more targeted forensic acquisitions. It should be noted that live triage tooling would leave its trace. This should be considered before execution.
Capabilities
Let us talk about what it collects! At the time of writing, the output data collected by Cat-Scale is saved to a tar.gz archive. On average we found that the resultant archive would be about 200 to 300 Mb which makes it fast to upload and download at scale.
Running the tool is straight forward.
$> chmod +x ./Cat-Scale.sh
$> sudo ./Cat-Scale.sh
Upon execution, Cat-Scale will clear the cli and will provide you updates on collection as it executes them.
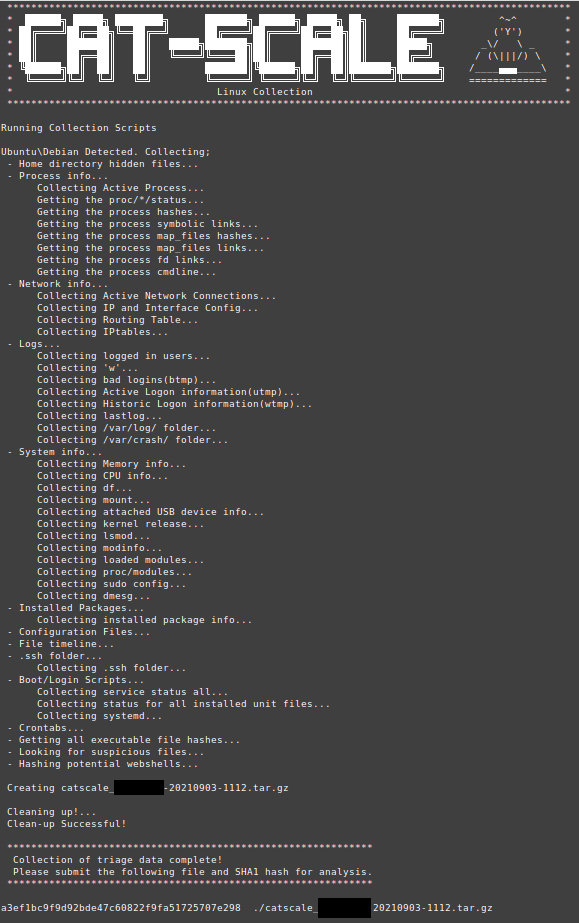
While you could extract the contents of the archive manually using your favourite archiving tool, we included a Bash script Extract-Cat-Scale.sh. This script iterates over the collected data to extract the archive into a specific folder structure that aids manual analysis or the ingestion of the data into an ELK stack.
The collected data is saved in the following folder structure:
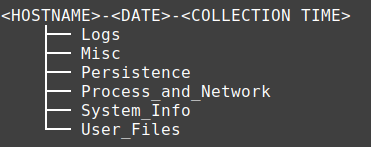
The above folders contain a collection of both live data, key files, and log data. While files collected from the system will keep their original name, output collected as a result of running a command will have the command in the file name with any relevant command options added alongside.
While the contents of these folders may vary depending on the OS Cat-Scale was run on, the output will be consistent on the supported systems and any console errors encountered during the collection would be logged into a text file "<HOSTNAME>-<DATE>-<COLLECTION TIME>-console-error-log.txt" in the root directory.
Provided below is a summary of what these folders contain and few of our favourite files within these directories. Cat-Scale does collect an extensive list of artefacts and we recommend getting familiar with it by simply testing it out on your analysis host and reviewing the output.
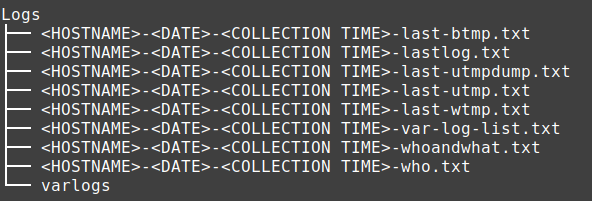
Logs
This folder contains a full copy of the /var/log folder and various text files generated as a result of running commands such as last, utmpdump, w and who. This folder is a great source of information if you are investigating active/historic logons, hunting for signs of rootkits, privileged command executions or ssh activity.
Contents of the root of Logs directory:
Persistence
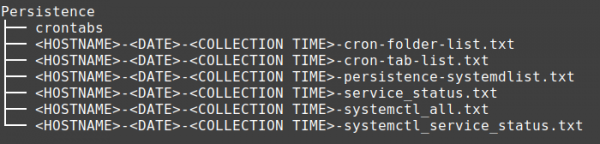
Threat actors often deploy some form of persistence to ensure that they maintain access to a system. This folder aims to capture signatures triggered by some of the main persistence techniques in a single location to help investigators identify any anomalies.
Please note that the System_Files and the User_Files folders also contain original copies of artefacts that may be utilised by the threat actors to install persistence. We chose to keep these folders separate as collections related to System_Info and User_Files can be bit of a mixed bag of artefacts that may have different relevance to the investigation based on the nature of the attack, i.e., insider threat, malicious configuration changes.
Contents of the root of Persistence directory:
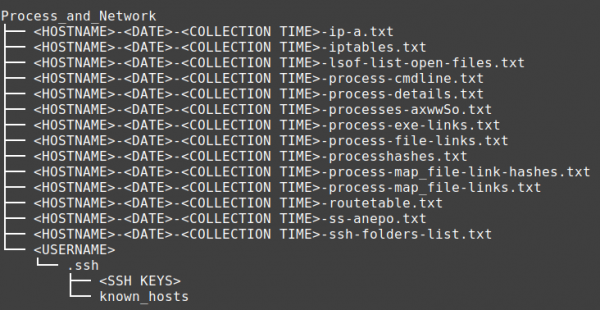
Process_and_Network
One of the greatest disadvantages malware has when it comes to hiding itself is that it must still be a running process. Being able to get a list active processes and network connections provides you with a goldmine of findings to direct your investigation. The data could be used to determine the scope of the infection across the estate or just to get a starting point in an investigation.
A Few noteworthy mentions from this folder are;
- processes-axwwSo.txt which contains the output of ps command, with executed options in the file name.
- processhashes.txt contains SHA1 hashes of the process binaries that were running at the time
- process-file-links.txt includes file descriptor links per process
- process-map_file-link-hashes.txt contains SHA1 hashes of the memory mapped files that may not be on disk anymore.
- ss-anepo, ss includes outputs specific to active/passive sockets, netstat is ran if ss is not available
Contents of the Process_and_Network directory:
System_Info
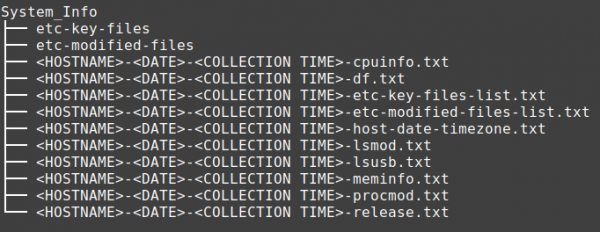
Information available in this folder can be divided into 3 categories.
- Information on the system such as the time zone, file system, operating system version
- Key configuration (etc) files that can provide information about the users on the system and may be used for malicious persistence
- Any file in etc folder that was modified in the last 90 days, in a server that configuration should be stable, this folder can provide quick insight into what the threat actor may have modified in the last 90 days.
Contents of the root of System_Info directory:
User_Files
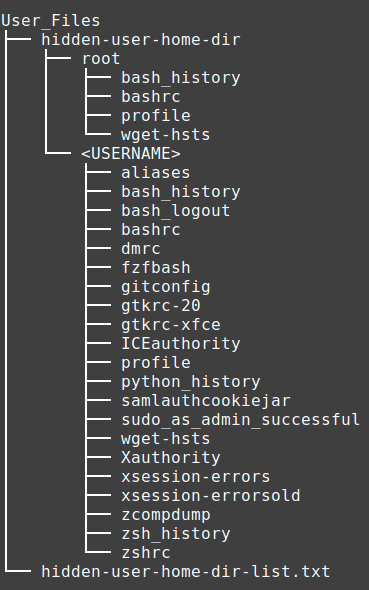
This folder contains the output of the get_hidden_home_files function which simply archives all hidden files in the root of the users' folders. As most investigators will know this will include command histories for various applications and user specific application configurations.
Contents of the User_Files directory:
Misc
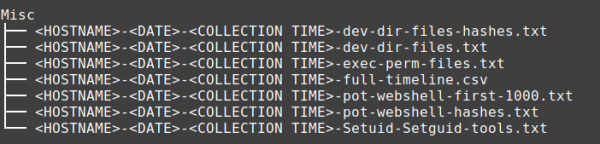
We named this folder Misc(miscellaneous) as it contains the output of various commands we found helpful to our investigations over the years such as *pot-webshell-first-1000.txt, *full-timeline.csv or *exec-perm-files.txt.
The *pot-webshell-first-1000.txt contains the first 1000 lines of all files with the extension of jsp, asp, aspx and php files which comes handy when dealing with a threat actor favouring web Shells. A significant use case for this file is collecting this data in a network of 200+ Linux hosts which can then be used to quickly YARA scanned for web shell signatures.
As the name suggests, *full-timeline.csv also comes in handy when looking for indicators across the network. This file contains various timestamps, metadata for files and directories in a csv format. Similar to Windows MFT timeline analysis, analysts can review the output to identify file/metadata modification and access around the time of interest. While we have experimented with utilising the file system debug tools to extract the creation time of the files and directories, we found that this process caused script to run for almost 10 times longer and the collected output had to be reformatted using additional scripting. Thus we opted for collecting information using the Find command. While this does not provide the creation timestamp for majority of the use cases, we found the other collected timestamps sufficed to perform triage analysis on hosts.
Reviewing recently modified files in /etc/ folder:

Another notable mention from this folder is *exec-perm-files.txt which collect SHA1 hashes of all files marked as executable, allowing you to query the hashes in your threat intelligence platform of choice for quick wins.Furthermore, if you are interested in creating timelines using file system debug tools, the PoC code for doing this on ext file systems can be found on https://github.com/56616c6f72/Emperor project in the Emperor.sh script as get_debugfstimeline function. Python script, pingu.py, converts the output to CSV is also provided in this github project.
Contents of the Misc directory:
Future of Cat-Scale
Cat-Scale is open-source and is updated as regularly as possible. We have been talking to various people from the industry to share the learning we have gained from it and to improve it wherever we can. We hope that we can encourage more people to join us on improving Cat-Scale.
We have various features we are working on such as;
- Identification of other forensics artefacts that may be relevant to incident responders
- Improving data ingestion by converting the output to json
- Building a set of detection rules that performs basic checks
- Support for other OSes such as OpenBSD
If you have any ideas or used Cat-Scale and have any feedback, do get in touch by emailing to cir@f-secure.com!