What the Fuzz
By Felix Schmidt on 23 January, 2019
Introduction
This blog post covers the basics of fuzzing, introduces several fuzzing tools and outlines a selection of recent fuzzing research in three sections.
The first section explains what fuzzing is on a high level basis and briefly discusses reasons for and against fuzzing. It further explains what you need to start with fuzzing yourself and what the architecture of a typical fuzzer looks like.
The second section introduces several fuzzing tools to give an overview tools are available and to ease the process of getting started with fuzzing. Although it is easier to just use an existing fuzzer, a self-written fuzzer or an adjusted existing fuzzer might yield better results. This is not a comprehensive list but rather a selection of examples for different fuzzing techniques.
The third section outlines a selection of recently published research about fuzzing. It will focus on publicly available research about novel fuzzing and test case generation techniques.
Now, let's dive in.
0 - Fuzzing 101
Introduction
This section explains what fuzzing is on a high level basis and briefly discusses reasons for and against fuzzing. It further explains what you need to start with fuzzing yourself and what the architecture of a typical fuzzer looks like.
What is fuzzing?
Fuzzing or fuzz testing is an automated software testing technique generally used to identify potential vulnerabilities in a program. Fuzzing a program is done by providing randomised input to it and record any test cases that caused a crash or a non-crashing memory corruption in the program. In a sense fuzzing is like a brute force search for vulnerabilities. Almost every software that expects some sort of input can be fuzzed - browsers, applications to view or edit files, system kernels, most APIs and other program interfaces, drivers, network daemons, web applications and so on.

Simple fuzzing doesn't need any information about the program and is therefore a black box testing technique. However, there are advanced fuzzing techniques that analyse or instrument the source code or the binary to tailor the generated inputs to the fuzzed program which will be the topic of one of the next blog posts of this series.
Why fuzzing?
Fuzzing is an automated way of finding bugs; ideally a fuzzer can simply run on a machine and be left alone. Since it doesn't require much manual interaction it can be a cheap testing technique. Manual testing on the other hand is very resource intense and the amount of bugs it reveals depends on the skills of the tester. A combination of fuzzing and manual testing is optimal since both techniques usually reveal different kind of bugs and they can educate the other.
The more complex an application gets the more bugs it will have as with growing complexity the attack surface grows as well. Manual tests for very complex applications take a lot of time and require good testing skills. For example if a company would decide to only manually test a browser it would need lots of skilled testers to be able to test the whole application before a next release is finished. A fuzzer can simply run permanently and test software before it is released. Most fuzzers scale quite well so if it is required to test faster and find more bugs you can just spin up more machines or more cores. Fuzzing can also be used for regression testing to make sure to not reintroduce any known bugs.
As a security researcher fuzzing is great because once a fuzzer is set up and running you can work on something else while the fuzzer - hopefully - finds bugs.
Common issues with fuzzing
Although fuzzing is a great and cheap method of finding bugs it is not always optimal. Depending on the application and the desired type of bugs that the fuzzer is supposed to find it can require a lot of time to set up. Especially self-written smart fuzzers that are aware of the input structure will take some work until it produces usable results.
A fuzzer is no replacement for other security measures. Even if you have the greatest fuzzer that reveals tons of vulnerabilities it is unlikely to find every vulnerability in a program. And if your fuzzer doesn't find any more vulnerabilities it doesn't mean that your program is perfectly secure. Fuzzing is just a good complement to other security measures like regular code audits and other secure development principles.
Fuzzers can produce many false positives, unexploitable bugs and duplicates. Therefore a review process is mandatory, either manual or automatic, which requires resources. The more complex the input gets the more complex the review process gets.
Maximizing the efficiency of a fuzzer is one of the hardest parts about fuzzing. The value of a fuzzer is generally determined by how many previously unknown bugs it reveals. To find more bugs a fuzzer needs to have a high crashes per test case ratio which is highly dependent on the quality of generated test cases. It's easy to pipe /dev/urandom to your target but the crashes per test case ratio will probably be too low to find anything in an appropriate time window. Simultaneously the execution time of a single testcase should obviously be as low as possible.
What is needed for fuzzing?
To start with fuzzing you need a target that takes an input. The more complex the application is the more likely is it to find bugs with a fuzzer. It can be in-house or third-party software depending on the use case. You need to think about the types of bugs you want to catch. A fuzzer needs to know when it found a bug so the easiest found bugs are those that lead to a crash, as that would indicate a potential security vulnerability.
When you found the application you want to fuzz and the types of bugs it should reveal it is necessary to think about what fuzzer to use. There are a lot of different fuzzing tools to choose from if you don't want to write a fuzzer from scratch. Some of them require some work to set up, others work quite instantly. Since the right choice of a fuzzing tools is important and difficult at the same time a selection of the most important fuzzing tools is introduced with one of the next blog posts of this series.
What types of bugs can a fuzzer find?
Theoretically it is possible to find every possible bug type through fuzzing. A fuzzer needs a detection mechanism to classify the behaviour of a program as unintended or malicious. Therefore some bug classes are a lot easier to find than others because they produce a clear misbehaviour. For example, memory corruption bugs leading to a crash when triggered are easy to detect. Logic bugs on the other hand can be very hard to detect since the program is not obviously misbehaving and predefining rules for detecting logic bugs can be tricky.
Architecture of a typical fuzzer
A typical fuzzer consists of three different parts. A test case generator which generates input to feed to the fuzzed program, a worker which executes the program with a given input and recognizes unexpected behaviour and a logger that is logging interesting test cases and everything that is needed to analyse a bug. Most fuzzers also include a server / master which orchestrates the other three parts and manages communication between them.
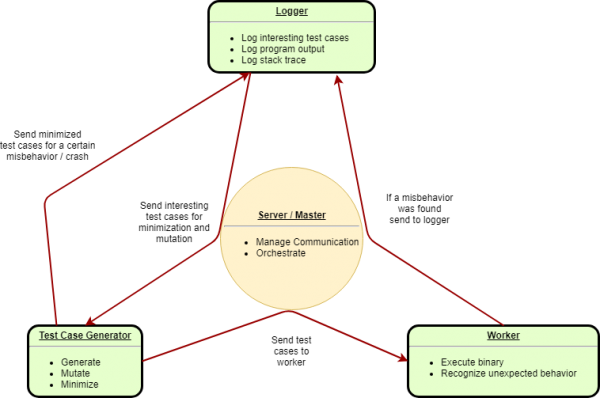
Test case generator
A test case generator is mainly responsible for creating new test cases. To create new test cases it can be aware of the structure of the input which is called a smart fuzzer. Conversely, a test case generator that isn't aware of the input structure is called a dumb fuzzer. Test cases can be generated from scratch or they can be mutated from existing test cases. Sophisticated fuzzers can also combine both generation and mutation of test cases.
Guided fuzzing
Test cases created by the test case generator differ greatly in quality. Therefore some kind of guidance is needed for the test case generator to decide which test cases to mutate or generate. The most common guidance heuristic is code coverage. In theory the more code coverage a fuzzer reaches the more bugs it will find. A test case generator can be configured to create test cases that were similar to test cases that revealed new coverage. Similar to coverage guided fuzzing basically every metric related to finding more bugs can be used as guidance for a test case generator for example data flow guidance.
Dumb fuzzing
A test case generator that doesn't require a model of the input structure to generate new test cases is called a dumb fuzzer. The advantage of a dumb fuzzer is that it needs no information about the input structure and is therefore suitable for fuzzing a lot of different programs without much adjustment. The biggest disadvantage with dumb fuzzing is that most inputs need some predefined structure or include checksums and the fuzzer will have a hard time generating valid input and therefore is mostly testing the parsing code of an application.
Smart fuzzing
The opposite of a dumb fuzzer is a smart fuzzer whose test case generator is aware of the structure of input files. The structure of an input file is called the input model. An input model can for example be the grammar of a programming language or a data format model. The advantage of a smart fuzzer is that it creates mainly valid input files which should lead to higher code coverage in the actual program. However, a smart fuzzer is generally highly specialised to a certain type of input and it requires a good input model to be able to create test cases that are likely to trigger bugs.
Mutation based fuzzing
Mutation based fuzzers create new test cases by mutating known test cases. Common mutation techniques include bit flipping, where random bits in the input are flipped, or moving, deleting or repeating data blocks in the input. The main advantage of a mutation based fuzzer is that it requires less work to set up. The crucial part for a mutation based fuzzer is to choose interesting test cases to mutate from. They need to be as distinct as possible to enable the fuzzer to reach as much code coverage as possible to make it more likely to reveal bugs. For example, if the target was an application to view and edit pictures and the chosen test cases to mutate from are only in PNG format it would be unlikely for the fuzzer to reach code that handles other file types.
Generation based fuzzing
Generation based fuzzers generate new test cases from scratch. Generation based fuzzers need to be aware of the structure of the input file or they will simply produce random bytes. Usually they need work to set up and are specialised to a certain input type. However, once up and running they tend to produce more code coverage than mutation based fuzzers and are therefore more likely to find distinct bugs.
Test case minimization
Over time test cases created by mutation tend to grow in size and complexity. This leads to higher execution time and it makes it harder to analyse interesting test cases. Smaller test cases are also better to focus fuzzing on interesting parts of the fuzzed software. Therefore the test case generation engine of a fuzzer should also be able to minimize test cases. The goal of minimizing test cases is to find the smallest test case possible while triggering the same behaviour the initial test case triggered. The same behaviour means in this case that either that the same crash is triggered or the same guidance requirement is met. For coverage guided fuzzing for example does it mean that the same interesting code blocks are hit in the minimized test case. This can be done by removing parts of the test case, feeding the target with the altered input and observe if the behaviour still fulfils the same requirements.
Worker
The worker is responsible for executing test cases supplied by the test case generator. It also needs to recognize unexpected behaviour.
Normally executing the test case is straight forward. The worker feeds the target with the given input and detects any signs of misbehaviour. A simple case would be to execute a binary that is compiled from a C-family Language, i.e., a binary that is prone to have memory corruption issues. In that case a crash is a typical misbehaviour which can be easily detected. Using compiler instrumentation with a tool like AddressSanitizer can help detecting non-crashing memory safety bugs.
Logger
The logger logs or stores every found crash and their respective test cases. If the fuzzer is guided by coverage it can also store any test cases that found new code coverage. Logging can ease the analysis of crashes with stack traces of a crash. Logging test cases that lead to a crash is crucial since otherwise a crash wouldn't be reproducible.
Summary
Fuzzing is a great automated continuous way of finding bugs. For developers fuzzing can be very helpful as it is able to find bugs very early, sometimes even before a bug got into a release. Fuzzing can also be used as a tool for regression testing to find reintroduced bugs. For security researchers fuzzing is a great tool to find bugs as it is able to uncover bugs that weren't found through a manual audit / penetration test and it can be kept running while working on something else.
The hardest part about fuzzing is to maximize the efficiency of the fuzzer. The efficiency of a fuzzer is given by crashes per test case and by test cases per second as the overall goal of the fuzzer is to find as many crashes in the smallest time possible.
The typical fuzzer consist of three components: a test case generator to generate input files, a worker that executes test cases and recognizes unexpected behaviour of the program being fuzzed and a logger that logs interesting test cases and potentially stack traces of crashes or malicious behaviour.
1 - Fuzzing Tools
This section briefly introduces several fuzzing tools to give an overview over what tools are available and to ease the process of getting started with fuzzing. Although it is easier to just use an existing fuzzer, a self-written fuzzer or an adjusted existing fuzzer might yield better results. This is not a comprehensive list but rather a selection of examples for different fuzzing techniques.
List of Introduced Tools
- Sanitizers
- Radamsa
- American Fuzzy Lop (AFL)
- Peach Fuzzer
- honggfuzz
- libFuzzer
- domato
- sqlmap
Sanitizers
While not specific to fuzzing sanitizers are a powerful tool for crash detection that inject assertions in the target program at compile time. The interesting sanitizers for fuzzing included in clang / clang++ are AddressSanitizer, ThreadSanitizer, MemorySanitizer and UndefinedBehaviourSanitizer. All sanitizers provide an extensive log when a crash happened including the type of vulnerability triggered and a stack trace of the program. They introduce CPU and memory overhead which is why they are rarely used in shipped applications. The choice of a sanitizer depends on the types of crashes supposed to be detected.
- AddressSanitizer (ASan) is the most commonly used sanitizer for fuzzing due to its ability to detect use-after-free, buffer-overflow vulnerabilities and other memory safety issues .
- ThreadSanitizer (TSan) is a sanitizer able to detect data race conditions. However, it is currently in beta status and introduces heavy memory overhead.
- MemorySanitizer (MSan) detects read access to uninitialized memory.
- UndefinedBehaviourSanitizer (UBSan) is used for detecting undefined behaviour in a program for example (signed) integer overflows or misalignment of pointers. Please refer to a full list of detectable undefined behaviour in the clang documentation.
Radamsa
Radamsa is a general purpose dumb mutation based fuzzer. This fuzzer is targeted at unexperienced testers due to its easy setup and usage. It tries to recognize data structures and mutates randomly based on different mutation engines with respect to the input structure. Here's a usage example from the manual:
$ echo "Fuzztron 2000" | radamsa
Fuzztron 4294967296
Despite its simple nature Radamsa helped finding many bugs in public software including major browsers.
American Fuzzy Lop
When talking about fuzzing there's no way around American Fuzzy Lop (AFL) by Michal Zalewski a.k.a. lcamtuf. AFL is a coverage-guided, mutation based dumb fuzzer, i.e., it doesn't need any information about the input structure but due to its intelligent design it is able to generate mostly valid input. It ships with a sophisticated fuzzing infrastructure including a testcase minimizer and a modified version of gcc and clang which manages compile-time instrumentation with sanitizers. A selection of bugs found with AFL is listed on Michal Zalewski's blog.
The predecessor of AFL is named bunny-the-fuzzer. Bunny-the-fuzzer was released in 2007 and was an evolutionary fuzzer that tried to respect the internal state of the program to generate better input. However, according to Michal Zalewski it performed barely better than random fuzzers (see historical notes of AFL).
Peach Fuzzer
The peach fuzzer is a highly flexible fuzzing framework. It can be either a smart or a dumb fuzzer, generating or mutating input depending on the configuration. Its main advantage is its ability to fuzz almost everything - it can produce file based inputs, fuzz network protocols, make web requests and fuzz state aware protocols. Due to its flexibility it needs a significant amount of configuration before the actual fuzzing, therefore it is targeted at experienced testers. Peach also offers a closed source enterprise edition with preconfigured data models for common protocols and file formats, more mutation algorithms, integrations for ticket systems and more.
libFuzzer
LibFuzzer is a coverage-guided in-process fuzzing engine using evolutionary test case generation. In-process fuzzing is a fuzzing technique where the fuzzing happens in only one process, i.e., for every test case the process isn't restarted but the values are changed in memory. This leads to a huge speed up compared to out-of-process fuzzing.
honggfuzz
Honggfuzz is similar to libFuzzer in that it is a feedback-driven evolutionary fuzzer. It supports several feedback methods other than coverage guidance though and includes an in-process and out-of-process fuzzing option. Honggfuzz has a multi-process and multi-thread architecture making it easy to use the potential of all cores with a single fuzzer instance.
domato
Domato is a DOM fuzzer written by Ivan Fratric and was used by Project Zero for their Great DOM Fuzz-off of 2017. Technically, domato isn't a fuzzer but rather a test case generator as it can only generate HTML, CSS and JavaScript based on a given, easily extensible grammar.
sqlmap
Sqlmap is an example of a fuzzer that isn't looking for crashes. It is used as a penetration testing tool for automatic detection and exploitation of SQL injection flaws.
Final Note
As already stated in the introduction this is just a small selection of fuzzing tools. You can find a more extensive list here.
2 - Recent Research
Fuzzing with code fragments
This paper by Christian Holler, Kim Herzig and Andreas Zeller introduces a novel fuzzer named LangFuzz. LangFuzz leverages a given grammar for a programming language to generate code, existing code samples and a mutation engine to create test cases. The internal representation of a test case is a tree with nodes being random code snippets from existing or generated code fragments. With this technique, LangFuzz is able to generate test cases that have a high probability of being syntactically correct while still reaching edge cases of a language. The authors found 105 vulnerabilities in the Mozilla JavaScript engine and 18 vulnerabilities in the PHP interpreter with LangFuzz at the time of publishing their research and it continues to find bugs today.
Not all bytes are equal: Neural byte sieve for fuzzing
This paper by Mohit Rajpal, William Blum and Rishabh Singh from the Microsoft research team examines using neural models to pick locations for mutations based on previous coverage results. A neural model vetoes AFL's suggested location of mutation for the input file if previous runs didn't reveal much new coverage for a mutation at this location. The authors found that this reveals significantly more coverage and crashes compared to a normal AFL run in 24 hours for small input files ( <100kB ).
libFuzzer-gv: new techniques for dramatically faster fuzzing
This bog post by Guido Vranken introduces metrics for fuzzing guidance other than code coverage. These include stack-depth-guided fuzzing which can help finding excessive recursion crashes and intensity-guided fuzzing which favours input that hits non-unique code paths multiple times to find slow inputs potentially leading to DoS vulnerabilities. The author implemented his guidance techniques in a fork of libfuzzer and published it on GitHub.
Improving Function Coverage with Munch: A Hybrid Fuzzing and Directed Symbolic Execution Approach
This paper by Saahil Ognawala, Thomas Hutzelmann, Eirini Psallida and Alexander Pretschner introduces a hybrid fuzzing techniques which combines fuzzing and symbolic execution. Symbolic or concolic execution is a technique to reach certain functions in a program by creating constraints representing branching conditions to reach a function within a code base and solving those constraints with an SMT solver. The hybrid technique used by Munch implements AFL as the fuzzing engine and a modified version of KLEE as symbolic execution engine. The conducted experiments suggest that using this hybrid approach leads to significantly higher coverage than fuzzing or symbolic execution on its own.
Skyfire: Data-Driven Seed Generation for Fuzzing
This paper by Junjie Wang, Bihuan Chen, Lei Wei, and Yang Liu presents an approach to generate seed files based on a probabilistic context sensitive grammar. They are trying to solve the issue that most generated test cases for a target that requires complex input files based on a context free grammar are rejected early in the semantic checking stage while most vulnerabilities hide in the application execution stage. The authors compared crawled examples from the web with seed files generated by Skyfire by seeding AFL with both seeds in separate runs. The AFL run with Skyfire seeded input files performed significantly better in terms of reached code coverage and found bugs.
Evaluating Fuzz Testing
This paper by George Klees, Andrew Ruef, Benji Cooper, Shiyi Wei and Michael Hicks examines fuzzing research itself. The authors assessed 32 recently published fuzzing research papers and found problems with the experimental evaluations in all examined papers. The main issue with most published fuzzing research is comparability of the results as no uniform measurement practice exists. Therefore, the paper suggests best practices for measuring new fuzzers or fuzzing algorithms such as "using a solid, independently defined benchmark suite", uniform timeouts and multiple test runs per fuzzing run. This blog post summarizes the proposed criteria for meaningful benchmarks for fuzzing.
Conclusion
Fuzzing research is a hot topic as almost every approach can be improved further by introducing new techniques and combining different approaches. Comparing fuzzing research is hard due to missing uniform benchmarking techniques.
This concludes this blog post about fuzzing. Thanks for reading.