Securing AEM With Dispatcher
By Robert Russell on 7 September, 2020
Intro
Adobe Experience Manager (AEM) is a popular Content Management System (CMS) that is used by a large and active user base to develop and deploy web applications. We have assessed several implementations and have found that despite many vulnerabilities being common knowledge, they are often still present in production deployments. In this blog post, I will be discussing common AEM vulnerabilities and some advice for defending your AEM instance against them using AEM’s Dispatcher. Although the sorts of attacks discussed in this post are well known, many still struggle with them, as remediation can prove tricky to get right. My goal for this post was to gather the relevant pieces of information in one place and help users understand why these issues happen, why their configuration isn’t working like they think it is, and to describe specific techniques for debugging their environment.
Let’s start with some background on AEM architecture. Content is created on an AEM author instance and then pushed out to one or more publish instances to be viewed by the outside world. However, instead of having application users directly interact with an AEM publish instance, they usually sit behind an instance of Dispatcher. Dispatcher integrates with web servers such as Apache and IIS and is used to make decisions about what to do with incoming requests. Dispatcher can be used for performance-related activities such as caching and load-balancing, but it is important for security as well, as it can be used to decide what requests should be rejected or allowed before they are ever able to reach the AEM instance. The architecture of a typical AEM deployment is shown below:
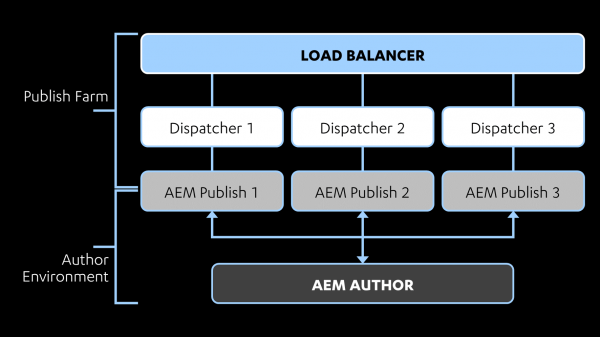
The configuration of Dispatcher is critical to the security of the AEM instance, as AEM has many dangerous features and administrative panels that, if exposed, could result in a range of issues, such as sensitive information disclosure, XSS, SSRF, and RCE. For more information on vectors that could be available to an attacker, I highly recommend this talk by Mikhail Egorov. Egorov’s slides also contain links to previous research that has been done on attacking AEM. However, the focus of this blog post will not be on attacking AEM, but rather on defending it by securely configuring Dispatcher. Note that Dispatcher configuration is not the only thing a sysadmin must get right if they want to secure an AEM instance. For example, default credentials should be changed, default accounts/content removed, and strict access controls should be configured using ACLs to prevent problems like anonymous users being able to create JCR nodes. Adobe has provided a Security Checklist that can be referenced for further information on how to address these problems. Although this checklist serves as a good starting point for overall AEM configuration, it can provide a false sense of security when it comes to Dispatcher configuration, as it doesn't address the type of bypasses we will cover in this post.
For our purposes, we will be focusing only on configuring Dispatcher because, as evidenced by the sorts of bypasses discussed by Mikhail Egorov, it can be a tricky thing to do. In fact, this blog post was sparked by concerns that have been communicated to us about the difficulty of preventing Dispatcher bypasses of exactly this sort, with many finding themselves struggling to understand why their allow-lists are not working as intended. In this post I will do the following:
- Describe some of the basics of AEM internals and Dispatcher configuration
- Run pentesting tools against an AEM instance protected by the default Dispatcher configuration
- Walk through an example Dispatcher bypass that leads to XSS against this setup
- Modify the configuration to mitigate this finding and all others reported by the tools
The goal is to get at the heart of the issue of why AEM is so tricky to secure. My setup is as follows:
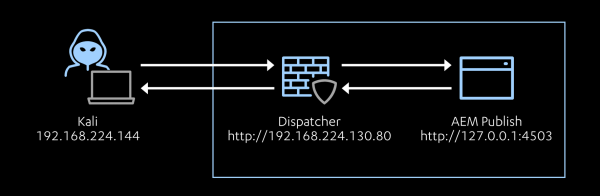
My AEM host is running the following software:
- Adobe Experience Manager 6.5.0
- Dispatcher build 4.3.3/apache-2.4-linux-x86_64-ssl1.1)
- Apache 2.4.38
- Debian 10
In addition, the publish instance is hosting the we-retail application, a sample application that comes stock with AEM.
Apache Sling
Apache Sling is a RESTful web application framework that maps URLs from HTTP requests to resources in an underlying content repository. As AEM uses Sling internally, and it is central to some of the security issues we will explore later, it is worth taking some time to go over the basics of how it works.
When receiving an HTTP request, instead of directly fetching a resource at the requested URL, Sling decomposes the URL into the following components: path, selector, extension, and suffix. This is shown below:

Source: https://docs.adobe.com/content/help/en/experience-manager-65/developing/introduction/the-basics.html
Sling then locates a script that best matches the values of these components, and this script dynamically renders the content that is served to the user. Several scripting engines are supported, such as ESP (ECMAScript Pages - essentially server-side JavaScript) and JSP (Java Server Pages). Sling uses a Java Content Repository (JCR) as the underlying content repository.
The steps taken after Sling decomposes a URL are as follows:
- First, Sling matches the request to a resource in the JCR. The path and extension portions of the URL are used to locate a content node within the JCR and the sling:resourceType property is retrieved from this node.
- Next, Sling uses the value of sling:resourceType along with the extension, selector and method from the request to locate a script to render the content.
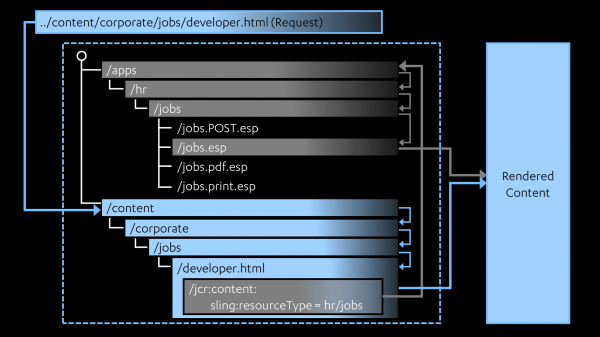
These steps are shown in the following image:
Source: https:/docs.adobe.com/content/help/en/experience-manager-65/developing/introduction/the-basics.html
Following the journey taken by the arrows in the above image, we can see how the path and extension from the request are used to search the JCR for a matching resource content node (blue arrows), and the value of sling:resourceType from this node is another path that is used to locate a subdirectory containing various ESP scripts (gray arrows). Note that, as shown in the above image, there could be several scripts that match. The method, extension, and selector from the request are used to find the best match. Finally, the chosen script is run to dynamically generate the page. This script can use extra information, such as the suffix and query parameters from the request, to determine how the page should be rendered. The important point here is that the script can render the page differently depending on the values of the URL components. More on this in following sections.
I also want to point out one final aspect of the inner workings of Sling that will be relevant later. The AEM Developing User Guide describes the steps taken when Sling locates the content node (the blue arrows in the above image):
- first Sling checks whether a node exists at the location specified in the request; e.g. ../content/corporate/jobs/developer.html
- if no node is found, the extension is dropped and the search repeated; e.g. ../content/corporate/jobs/developer
- if no node is found then Sling will return the http code 404 (Not Found).
We will revisit this process in later sections.
Dispatcher Basics
Dispatcher configuration is done in the dispatcher.any file. This file has a /filter section that contains rules that are used to determine what to do with a request. Each rule contains a /type (either allow or deny) and patterns that are checked against the request line of incoming HTTP requests for example: /method, /url, /query, and /protocol. As an example, the following /filter section contains one "deny" rule named /0001 that matches GET requests for "/index.html".
/filter{
/0001 { /type "deny" /method "GET" /url "/index.html" }
}Patterns can also contain * as a wildcard character, for example, the following rule matches all URLs under the /var/ directory.
/0028 { /type "allow" /url "/var/*" }The double quotes around a pattern make it a simple pattern. For more advanced pattern matching, Dispatcher > 4.2.0 allows POSIX Extended Regular Expressions by surrounding a pattern in single quotes instead. For example, the following rule matches all requests where the method is either GET or HEAD:
/0001 { /type "allow" /method '(GET|HEAD)' }Dispatcher also allows you to match patterns against URL components as decomposed by Sling using /path, /selectors, /extension and /suffix, as shown in the following rule from the default dispatcher.any file that ships with Dispatcher:
/0081
{
/type "deny"
/selectors '((sys|doc)view|query|[0-9-]+)'
/extension '(json|xml)'
}You can also match the entire request line using /glob. However, in the Dispatcher documentation, Adobe says this shouldn’t be used:
Filtering with globs is deprecated in Dispatcher. As such, you should avoid using globs in the /filter sections since it may lead to security issues.
However, Adobe does use this property in the first rule of the /filter section in the default dispatcher.any file:
# Deny everything first and then allow specific entries
/0001 { /type "deny" /glob "*" }As the comment indicates, the idea here is to use an allow-list approach by initially catching all requests with a deny rule, and then allowing expected requests through with subsequent allow rules. The important thing to note here is that only the LAST rule that matches a request will take effect. This means that if a request matches a deny rule, but then also matches an allow rule further down the list and nothing else after that, the request will be allowed despite having matched a deny rule.
In the following sections, we will be debugging our Dispatcher configuration. Therefore, when requests are either allowed or denied by dispatcher, it will be useful to know which rule it was that took effect. As such, I wanted to make a note about logging. The Dispatcher installation guide has the following example section to be added to the apache configuration:
<IfModule disp_apache2.c>
DispatcherConfig conf/dispatcher.any
DispatcherLog logs/dispatcher.log
DispatcherLogLevel 3This page also has the following description of the log levels:
0 - error messages only.
1 - errors and warnings.
2 - errors, warnings and informational messages
3 - errors, warnings, informational and debug messages.
Note : It is recommended to set the log level to 3 during installation and testing, then to 0 when running in a production environment.
However, there is an additional log level that is not mentioned in this page, log level 4, or “trace logging”. Trace logging is the only way to have Dispatcher log which rule was enforced for a request. This will be invaluable to us as we debug our configuration, so we will set it to this level. However, as noted by the installation guide, the log level should be reduced after configuration is completed.
The following snippet from my dispatcher.log file shows two log entries for a request that was denied by Dispatcher. In the first, we can see that the request was blocked by the rule /0001 (the deny all rule). This log entry is marked with a [T] indicating that it was made at the trace logging level. The second entry was made at the debug level (as indicated by the [D]) and simply tells us the request was rejected without displaying the rule that took effect.
[...] [T] [...] Filter rule entry /0001 blocked 'GET /home/users/p/pt4fL3_iu-IHqYrITiEg.infinity.json HTTP/1.1'
[...] [D] [...] Filter rejects: GET /home/users/p/pt4fL3_iu-IHqYrITiEg.infinity.json HTTP/1.1Note that although the default dispatcher.any file uses a numbering scheme to name rules, this is not actually required. Rules can be given descriptive names to aid in debugging. For example, I renamed rule /0001 to /deny_all as shown below:
/deny_all { /type "deny" /glob "*" }Viewing the log file now makes it more clear why a request was rejected:
[...] Filter rule entry /deny_all blocked 'GET /home/users/p/pt4fL3_iu-IHqYrITiEg.infinity.json HTTP/1.1'The /filter section of the default dispatcher.any file is included below. Note that this file contained several rules that were commented out. To save space, I have removed all the comments and only included rules that are active in the default configuration. This default set of rules can be used for reference as we continue forward into the next section.
/filter
{
/0001 { /type "deny" /glob "*" }
/0023 { /type "allow" /url "/content*" }
/0041
{
/type "allow"
/extension '(clientlibs|css|gif|ico|js|png|swf|jpe?g|woff2?)'
}
/0062 { /type "allow" /url "/libs/cq/personalization/*" }
/0081
{
/type "deny"
/selectors '((sys|doc)view|query|[0-9-]+)'
/extension '(json|xml)'
}
/0082
{
/type "deny"
/path "/content"
/selectors '(feed|rss|pages|languages|blueprint|infinity|tidy)'
/extension '(json|xml|html)'
}
}From Dispatcher Bypass to XSS
In this section we are going to explore how the previous concepts tie together, and why Dispatcher configuration can be tricky to get right. We will start by running some tools against an AEM publish instance sitting behind the default Dispatcher configuration. This publish instance is running the sample we-retail application that comes with AEM. We will then examine a finding reported by one of these tools and see step by step how a Dispatcher bypass can be constructed and, in this case, ultimately turned into an XSS vulnerability.
The tools we will be using automatically attempt to find Dispatcher bypasses and are listed below:
- https://github.com/0ang3el/aem-hacker (credits to Mikhail Egorov)
- https://github.com/Raz0r/aemscan (credits to Arseny Reutov)
When run against our AEM instance, these tools report numerous findings:
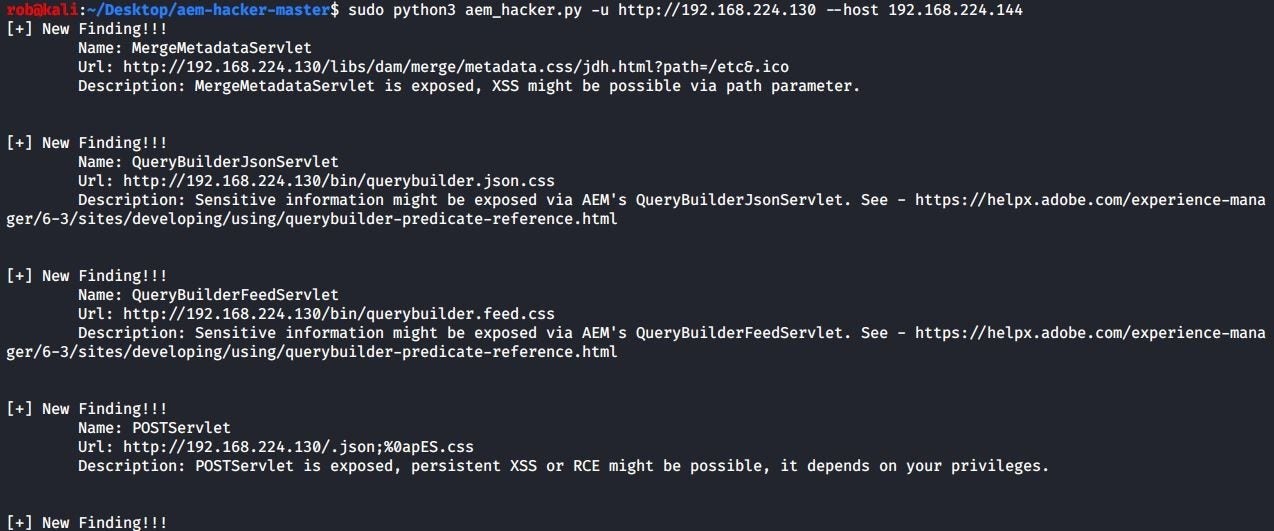
aem-hacker
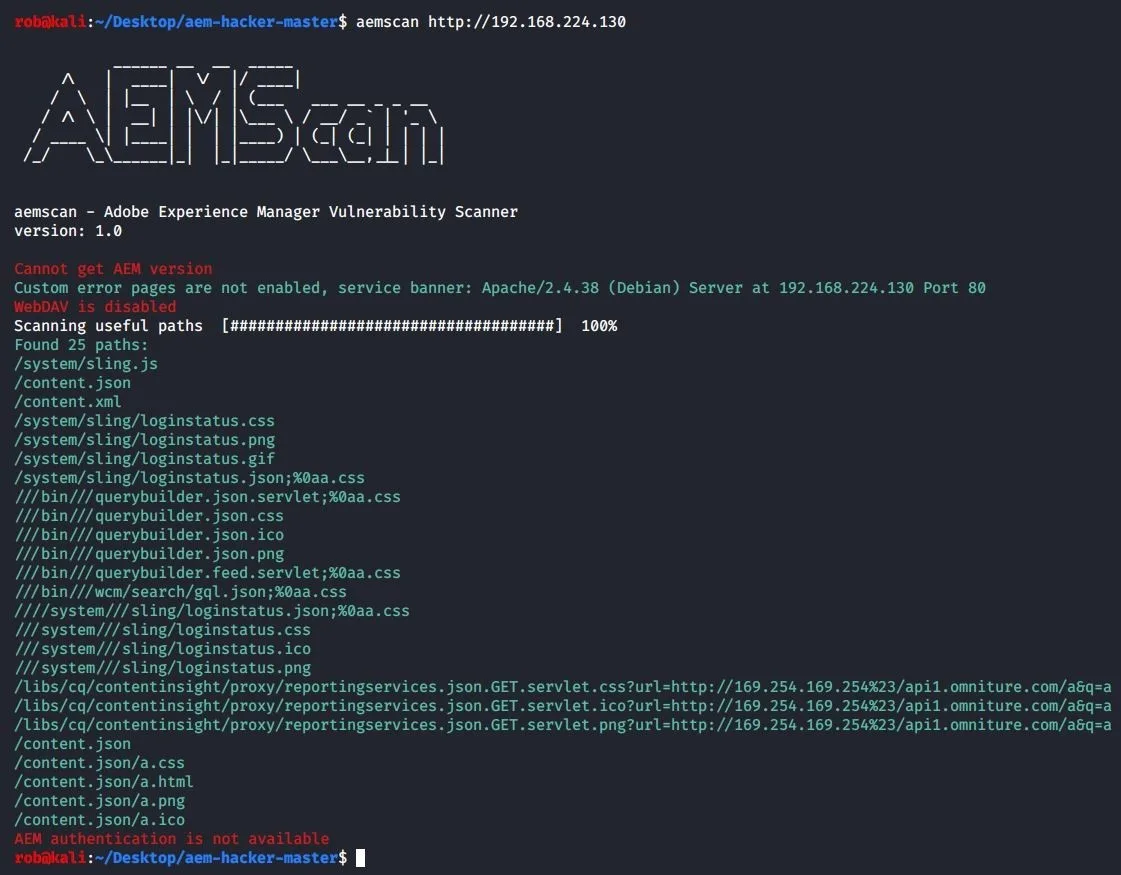
aemscan
To begin our analysis, lets start with the first finding reported by aem-hacker:
[+] New Finding!!!
Name: MergeMetadataServlet
Url: http://192.168.224.130/libs/dam/merge/metadata.css/MsV.html?path=/etc&.ico
Description: MergeMetadataServlet is exposed, XSS might be possible via path parameter.The finding says the MergeMetadataServlet is exposed. The following screenshot shows this endpoint being viewed in the browser on my local publish instance (I use the direct URL http://localhost:4503/libs/dam/merge/metadata?path=/etc&.ico so that the request does not go through Dispatcher):

Let me try to view the same page from my attacking machine (This request will go through Dispatcher):
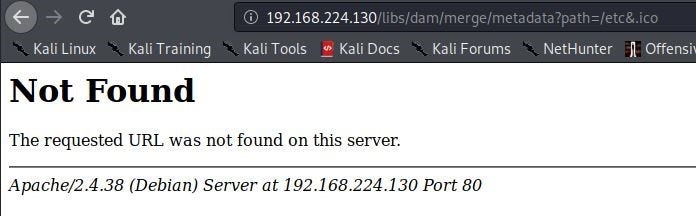
This returns a 404. It looks like this request was blocked. We can confirm this by looking at the Dispatcher logs. I find the following log entries confirming that this request was indeed blocked by rule /0001:
[...] Filter rule entry /0001 blocked 'GET /libs/dam/merge/metadata?path=/etc&.ico HTTP/1.1'
[...] Filter rejects: GET /libs/dam/merge/metadata HTTP/1.1This is the first rule that denies everything:
/0001 { /type "deny" /glob "*" }As none of the following rules match the request, this is the one that sticks. However, lets now try to append a .css extension to the URL (http://192.168.224.130/libs/dam/merge/metadata.css?path=/etc&.ico):

As shown above, appending a .css extension allowed us to access the page. Why? Time to check the logs to see which rule let this request slip past the filter:
[...] Filter rule entry /0041 allowed 'GET /libs/dam/merge/metadata.css?path=/etc&.ico HTTP/1.1'The request was first denied by /0001 but then later allowed by the following rule (recall it is the last match that sticks):
/0041
{
/type "allow"
/extension '(clientlibs|css|gif|ico|js|png|swf|jpe?g|woff2?)'
}Ok, so this rule allows the request to get through Dispatcher, but why does this work in the sense that the page is served even though metadata.css doesn’t actually exist? Recall from the section on Apache Sling the process Sling uses to map a URL to a JCR content node. In particular:
if no node is found, the extension is dropped and the search repeated
So we can append any of these allowed extensions just to get our request to match rule /0041 so Dispatcher will let it through, and it doesn’t matter because Sling will simply discard the extension anyway when it can’t find a matching content node and proceed to locate the node we wanted. I find the purpose of rule /0041 to be a bit mysterious, as in many cases it essentially allows an attacker to overcome the deny all rule, as long as the request is not blocked by another rule further down the list, effectively turning the allow-list into a deny-list.
We have now successfully bypassed Dispatcher, but the aem-hacker output mentioned that we can perhaps turn this into XSS via the path parameter. Let’s examine this parameter and see if we can accomplish this. To start, we try the following payload:
http://192.168.224.130/libs/dam/merge/metadata.css?path=/etc<img+src=x+onerror=alert(1);>&.ico

It looks like our input is reflected but is rendering as text instead of code. Lets’ open Burp and take a closer look.

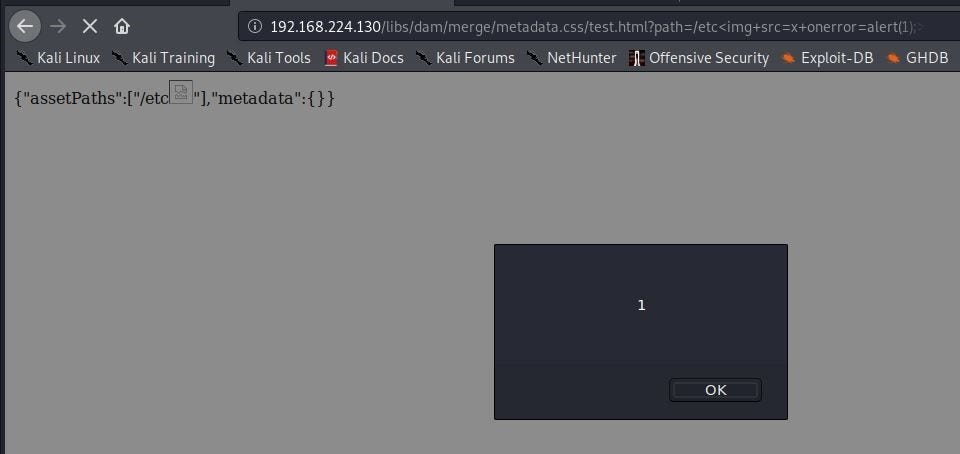
As we can see above, our payload is included in the response but won't fire as the page is returned as Content-Type: text/css. It looks Sling is rendering the content type of the page based on the extension we provided, which means we can control the content type to at least some extent. The problem is we are limited to the extensions allowed by rule /0041 if we want to bypass Dispatcher, and this does not include .html. Is there a way around this? It turns out there is. Recall from the Sling section that the suffix component of the URL could potentially influence how the page is rendered. Let us see what happens when we add a suffix ending in .html to the URL:

Nice! Looks like the content type was changed. We finally confirm the payload fires within the browser:
The Fix
Now that we have identified the problem with our Dispatcher config, it is time to see if we can do better. Recall that the problem rule that allowed the Dispatcher bypass was rule /0041, so the first step was to remove it. I then modified the following rule to make it more restrictive because it was resulting in some other findings reported by the tools (for example access to /content.json):
/0023 { /type "allow" /url "/content*" }To start, I replaced the above with the following:
/fix
{
/type "allow"
/path "/content/we-retail/*"
}Next, I used the following process to incrementally improve my configuration:
- Attempt to manually use the application (it may be broken if the policy is too restrictive)
- View the Dispatcher logs to identify which necessary requests may have been blocked
- Modify the Dispatcher configuration to allow the necessary requests
- Run the tools to ensure that the configuration update did not introduce any new findings
- Repeat this process until both the app functions correctly and the tools report no findings
Writing good rules can be difficult, but sensibly organizing the directory structure of the site can make things easier. For example, keeping all JavaScript for your site under /content/mysite/scripts/ and all images under /content/mysite/images/. Then you can deny all requests and only allow GET requests with a .js extension for /content/mysite/scripts/* or with image file extensions for /content/mysite/images/*. This ensures that higher levels of the directory structure can’t be reached, such as those containing dangerous AEM functionality.
The above process took some experimentation, but I ended up adding the following rules to the default configuration (after removing /0023 and /0041):
/fix
{
/type "allow"
/path '(/content/we-retail/.*|/content/dam/we-retail/.*|/conf/we-retail/.*|/var/commerce/.*|/libs/cq/i18n/.*)'
}
/allow_clientlibs
{
/type "allow"
/path "/etc*"
/extension '(clientlibs|js)'
}
/allow_currentuser
{
/type "allow"
/url "/libs/granite/security/currentuser.json"
}
/allow_csrf_token
{
/type "allow"
/url "/libs/granite/csrf/token.json"
}
/allow_logout
{
/type "allow"
/url "/system/sling/logout.html"
/query "resource=/content/we-retail/*"
}Note that, according to The Dispatcher Security Checklist caching must not be used for /libs/granite/security/currentuser.json. To accomplish this, I added the following entry in the /rules section of the /cache section of dispatcher.any:
/currentuser
{
/glob "/libs/granite/security/currentuser.json"
/type "deny"
}Now, the XSS attack from the previous section is blocked by Dispatcher!
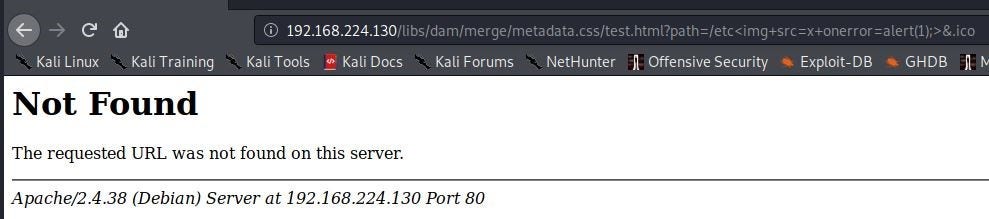
Not only that, both of our AEM testing tools reveal no findings:

aem-hacker
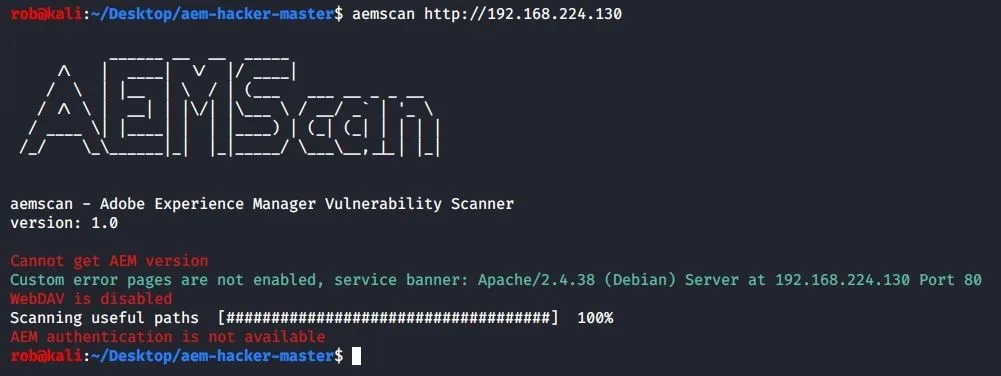
aemscan
Conclusion
Hopefully, this blog post was helpful in illuminating some of the quirks and gotchas of AEM and Dispatcher and providing a deeper understanding of some of the behavior that can make it a bit tricky to secure. As always, a configuration should be tested with the same techniques an attacker would use, and tools such as trace logging should be used to pinpoint the exact cause of issues. This process should be iterative and not static, and experimentation is often necessary. I hope the process I described will be useful to sysadmins looking to secure their AEM deployment.