Prince of the Honeycomb
By on 15 November, 2019
This story begins with a request for an internal penetration test in November of last year:
Countercept[1] (WithSecure’s Managed Detection and Response service) implemented a few new features in Honeycomb (its client-facing Ruby on Rails web application). As it’s good practice, the development team asked for a whitebox penetration test of the newly implemented functionality before releasing it to customers, particularly focused on reviewing some changes to the authentication mechanism.
Let’s work
After a thorough review of the newly implemented functionality yielded no significant findings, there was still some time left on the test. We decided to review the rest of the application once more. It was immediately obvious that the application had received considerable scrutiny before: code quality was high and a defensive coding style was used consistently throughout the project, e.g. safe-by-default templating and either parametrized or properly sanitized SQL queries. A few days into the review, not even a single XSS issue had popped up.
My name is Prince
Desperate times require desperate measures, so we decided to have a look at potentially vulnerable third-party products used by the application. One feature stood out as interesting: Honeycomb is able to generate reports and allows to export those as PDF files using a HTML-to-PDF conversion tool called prince[2]. Metadata in the resulting PDF indicated that the version in use was 11.4.

It quickly became apparent (from reading the documentation and playing with the command line utility) that the tool is not safe for use with untrusted input. For example, rendering an iframe-element with the src-attribute set to a local filename will dump the file contents into the resulting PDF. This means that any injection into the report-HTML will lead to (at least) file disclosure and a SSRF vulnerability.

While this seemed like a very interesting attack vector and got our hopes up, frustration quickly ensued as we weren’t able to discover any injection points without proper sanitization.
Y’all Want Some More?
Accepting that there are no HTML injection vulnerabilities which we could leverage, we took a step back and had another look at the application logic. Something stuck out as odd: the Honeycomb dashboard showed a few pie diagrams (rendered using JS and some canvas-code) which showed up in the PDF report as well, however there was no trace to be found of any server-side graphics rendering going on. A quick look at the HTTP traffic when exporting the report showed that the application exported the canvas as a PNG file using the toBlob() method and uploaded the result to the server which would save it in a temporary file (named by hashing the uploaded data and appending “.png”). The application would then insert an img-tag into the report-HTML with the src-attribute set to the temporary file to have prince render the image into the PDF.

Let’s Go Crazy
This presents another attack vector that doesn’t get much scrutiny in most web-application penetration testing: if there are issues in the way prince handles image files during rendering, we might be able to trigger those by uploading a malicious image. A few experiments quickly revealed that the filetype was inferred from the image data as opposed to the file ending (at least for binary image files, SVG would only be rendered with the correct ending). This opened up a lot of additional attack surface as the application supports JPG, GIF and TIFF as well - exciting news for a security researcher! We proceeded with a quick-and-dirty way to assess the security posture of image parsing code and threw a few Proof-of-Concept files for publicly known, old vulnerabilities in libjpeg, libpng, libtiff and giflib at it. While this didn’t immediately yield exploitable-looking crashes, one of them triggered a NULL-pointer dereference issue and crashed prince – demonstrating that there are likely more memory-safety issues that may be triggered by uploading malicious PNGs \o/
The Software Formerly Known As Prince
A closer look at the prince 11.4 binary revealed that it was a statically linked, 14MB big ELF binary without ASLR or stack cookies (with w^x enabled though). Motivated by those interesting results, we decided to look for more, potentially exploitable issues as there was still some time left on the project.
While looking for more elaborate ways of fuzzing the software, we quickly fired up AFL[3] against it using the above mentioned corpus of Proof-of-Concept files and it only took a few minutes before crashes started coming in.
Purple (0day) Rain
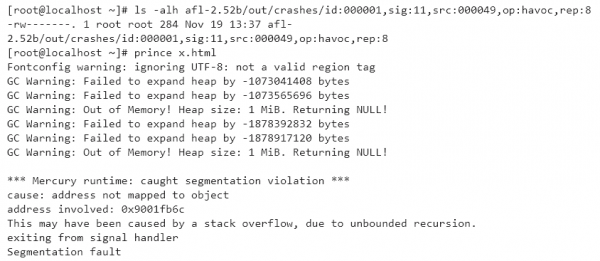
At 13:37, the fuzzer hit a crash with a corrupted TIFF-file that exhibited a strange, unmapped address. TIFF (Tagged Image File Format) is a container format that holds header tags and data tags (enabling multiple images in a single file for example) with header tags including metadata like ImageWidth, ImageHeight or SamplesPerPixel. Deconstructing the testcase revealed that the image had huge values for ImageWidth and ImageHeight. However, the version of libtiff that was statically linked to the binary didn’t exhibit any issues relating to oversized images. What’s going on here?
Surprise!
Inspecting the binary in a debugger revealed something unexpected: prince is written in Mercury[4], a strongly typed logic programming language with a syntax analogous to Prolog. This raised some questions: Mercury is a memory-safe language, however we’re obviously seeing a memory corruption issue. As it turns out, this lead us very close to the root-cause of the bug – interfacing between Mercury code and native code (i.e. libtiff). The libtiff API requires the user to manually allocate an appropriately sized (e.g. ImageWidth multiplied by ImageHeight) destination buffer before calling the decoding routines. While libtiff calculated buffer sizes correctly, the destination buffer size calculation performed by prince exhibited a signedness issue which led to the allocation of an undersized heap-buffer.
Do it all night
Armed with an arbitrary-length heap-buffer overflow, it’s time to devise a plan for exploiting the issue with the goal of achieving command execution via a write-what-where primitive. On a high level, we want to craft a TIFF-file with multiple entries that achieves the following:
- allocate an appropriately sized destination buffer that will end up adjacent to the parser state in memory
- use the overflow to corrupt the parser state, changing the saved destination buffer pointer to an arbitrary address, e.g. the GOT-entry of some target function that is invoked with the first argument pointing to controlled data
- parse some more data which will now be decoded to the target address, achieving an arbitrary write primitive – we use this to overwrite a suitable GOT-entry with the address of system()
- have the program invoke the target function chosen in step 2, leading to a call to system() with a controlled argument to achieve command execution.
Down a long, lonely road
While this may sound like a straight-forward plan for exploitation in theory, practically it involved multiple days of intense hunting for suitable overwrite targets, constraint-solving and finally troubleshooting.
We ended up using the GOT-entry of fread(void *ptr, size_t size, size_t nmemb, FILE *stream) as the overwrite target. The TIFF-file is read from disk row-by-row, so fread will be called multiple times, reusing the same buffer every time. If the last row that was read from the file (while fread()s GOT-entry is still intact) contained a shell command, this satisfies the necessary condition of the first argument pointing to the payload for command execution.
However, even after everything was in place and we verified in the debugger that system() is called with the desired argument, command execution would fail inexplicably. Increasingly frustrated, we figured out that the call to fork() in system() failed as the VM on which the exploit was developed ran out of memory due to the huge allocations involved. Luckily the Honeycomb server had enough memory for the exploit to work and eventually we ended up seeing this:
$ id
uid=501(honeycomb) gid=501(honeycomb) groups=501(honeycomb)
Everything could be so fine
To conclude, here are the key takeaways we learned from this assessment:
- Be mindful of third-party code handling untrusted data (especially when media files are involved, think ImageTragick, GhostScript vulnerabilities or ffmpeg)
- Keep looking out for new attack surfaces that might have received less scrutiny than the “classic” ones
- “memory safe language” != “no memory corruptions”
Timeline:
19.11.2018: Issue discovered in Prince (third-party software) - https://www.princexml.com/
22.01.2019: Issue reported to third-party vendor (YesLogic Pty. Ltd) - https://www.princexml.com/company
01.02.2019: Confirmation from vendor that the issue will be fixed in the next release
01.04.2019: Prince 12.5 released - https://www.princexml.com/forum/topic/4131/prince-12.5