Machine Learning Accuracy Forecast
Machine Learning in a Changing World
The only constant in the world nowadays is change. This is no different in machine learning, and the data that machine learning models are trained on. Therefore, developing a machine learning model does not stop once we have trained and deployed the model: we should also monitor the deployed model and data, to make sure that the model keeps performing as expected.
The use case we look at in this post is a host classification system. The machine learning model in this system uses information about the host activity as input, e.g., processes launched, domains accessed and extensions of files opened, to classify the host as technical, non-technical or server.
However, host activity may change significantly over time, causing the model performance to deteriorate. By monitoring the model, we can respond to and mitigate issues once they are detected, by retraining or otherwise updating the model.
Challenges in Performance Monitoring
To know how well a model is doing, we need to know how close its predictions are to the ground truth. However, while the ground truth is typically available for the training data of the machine learning model, it is typically missing for the data on which the model makes its predictions. If we knew the ground truth, we would not need a machine learning model in the first place! 😊

So, how can a model know how well it is doing if the ground truth labels are not available?
One way to do that is to try to measure directly how much the input data is changing over time (also known as data drift detection). The idea behind this is that if the data changes significantly, compared to the training data, the model may not generalize well to this data. However, data drift can be harmless in practice, and we observed for this use case that data drift did not correlate well with actual model performance. Over several months, we observed consistently high accuracy and recall for our machine learning model while the distribution of its input data was changing noticeably.
Another approach, which we investigated here, is to look at how certain a model is of its predictions, and to compute the average model uncertainty over all its predictions for each class. If a model is very certain of its predictions, then things are likely fine. However, if a model gets more and more uncertain of its predictions over time, then it may be a sign that we need to update it.
Measuring Average Model Uncertainty
Since we want to monitor model performance in a setting where ground truth labels are not (yet) available, our main metric of interest is average model uncertainty. Specifically, we monitor the entropy of predicted class probabilities:
As an example:
If the model predicts class probabilities (0.01, 0.04, 0.95) for classes technical, non-technical and server, then it is very certain of the class being server (predicted class probabilities have low entropy).
If the model predicts class probabilities (0.40, 0.21, 0.39) for classes technical, non-technical and server, then it will decide that the class is technical, but we can say it is less certain of its decision (predicted class probabilities have high entropy).
Once we have gathered a set of predictions, we reduce these to a per-class uncertainty score by aggregating over all samples per predicted class. These are the scores that we monitor.
The intuition behind this metric is that once samples move closer to decision boundaries (and the model becomes more uncertain of its predictions), they are more likely to be misclassified. Therefore, model uncertainty (entropy of predicted class probabilities) can be a proxy for actual model performance: if the model uncertainty goes up, the model performance goes down, and vice versa.
So, does it work?
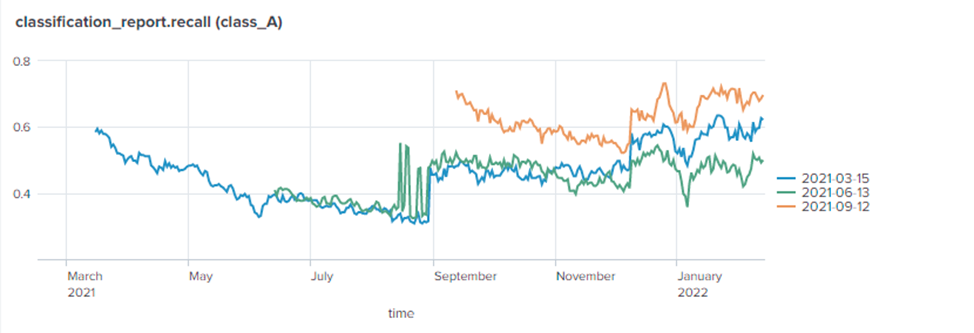
To validate the approach, we evaluate it on data for which we have the ground truth labels available. Recall is the main performance metric to optimize for this use case: we want to maximize the number of hosts the class of which we correctly identify. Other use cases may prioritize accuracy or other metrics. For several models we compare:
actual model performance by measuring recall for a particular class, which measures how many samples of that class are correctly classified (computed with ground truth labels)
average model uncertainty for the same class (computed without ground truth labels).
")
For the recall we can see that:
Retraining a model generally improves its performance.
Model performance varies over time, and after an initial drop, it increases back (which may point at the existence of seasonal trends, although more data is needed to say for sure).
Around the turn of the year, all models suddenly show a drop in performance.
For the average model uncertainty, we can see that:
As model performance deteriorates, average model uncertainty increases.
Average model uncertainty shows trends similar to recall, just in the opposite direction (when uncertainty decreases, recall increases), exhibiting also more subtle variations.
Around the turn of the year, average model uncertainty for all models suddenly peaks, which is well correlated with a decreased recall.
Based on these observations, the average model uncertainty provides a good indication of actual model performance in the considered use case, and it can be used as an indicator of deteriorating model performance.

Takeaways
Predicting model performance by looking at data drift is not always effective, since data drift can be harmless.
The average model uncertainty metric can act as a good proxy for the actual model performance and it can be used as an additional tool to monitor models in production, using only unlabeled data.
In response to detected model deterioration, the model can be retrained, and specific samples can be investigated and correctly labeled based on either model uncertainty (for unlabeled data), or loss (for labeled data).
These conclusions were drawn from the study of our use case, and they may not generalize to some other use cases, in which a combination of data drift and model uncertainty monitoring may be necessary to better predict changes in model performance. The best method for performance monitoring using unlabeled data will always depend on the machine learning model and the nature of the data used in a particular application.
Acknowledgement
This work has been partially supported and funded by Business Finland as part of the Eureka ITEA3 IVVES project. IVVES aims to systematically develop Artificial Intelligence approaches for robust and comprehensive, industrial-grade Verification & Validation of “embedded AI”.