Abusing access to mount namespaces through /proc/pid/root
By Pasi Saarinen on 11 June, 2020
Containers are used to isolate workloads from the host system. In Linux, container runtimes such as Docker and LXC use multiple Linux namespaces to build an isolated environment for the workload.
Due to this, a large part of the security research on containers and namespaces focus on exactly that: container breakouts. However, in some cases attackers are able to abuse containers and namespaces to escalate their privileges on an already compromised host. In this blog post we focus on such abuse.
We show how Docker containers running with default privileges, without the '–privileged' flag can be abused for privilege escalation if an attacker has root in the container and a shell outside of the container. Additionally we describe how a common class of vulnerabilities, namely symlink following, can be made much worse with the use of namespaces.
Quick intro to namespaces
The Linux kernel exposes seven namespaces that are used to isolate specific parts of the system from the workload. The PID namespace for example allows a process and its children to have an isolated view of the running processes on the system. The network namespace allows a set of processes to have their own view of the network, which is used to give containerized workloads their own IP address.
Here we focus on the mount namespace and the user namespace. The former allows a set of processes to have their own view of the filesystem and the latter allows a user to gain access to actions previously only allowed for root users – as long as those actions only affect their own namespace.
One special feature of the mount namespace is that they can be accessed through the /proc/PID/root/ and /proc/PID/cwd/ folders. These folders allow processes in a parent mount namespace and PID namespace to temporarily view files in the mount namespace of another process. This access is a bit magical and has some restrictions – for example, setuid executables will not work and device files are still usable even when /proc is mounted with the ‘nodev’ option.
Abusing Docker containers for privilege escalation
Lets start by abusing the fact that nodev does not apply.
In this scenario, we have an attacker with root within a Docker container and a shell on the host outside the Docker container. Docker containers do not use user namespaces; a root user within the container has root access outside the container. However, Docker removes a bunch of capabilities from the root user in a container to ensure that they cannot affect anything outside the container.
By default, a Docker container has the following capabilities:
cap_chown,cap_dac_override,cap_fowner,cap_fsetid,cap_kill,cap_setgid,cap_setuid,cap_setpcap,
cap_net_bind_service,cap_net_raw,cap_sys_chroot,cap_mknod,cap_audit_write,cap_setfcap+eipMost of these capabilities are hard to abuse, for example, the cap_kill allows root in the container to kill all processes it can see, which is limited by the PID namespace, effectively only allowing processes within the container to be killed.
However, as the container has the cap_mknod, a root user within the container is allowed to create block device files. Device files are special files that are used to access underlying hardware & kernel modules. For example, the /dev/sda block device file gives access to read the raw data on the systems disk.
Docker ensures that block devices cannot be abused from within the container by setting a cgroup policy on the container that blocks read and write of block devices.
However, if a block device is created within the container it can be accessed through the /proc/PID/root/ folder by someone outside the container, the limitation being that the process must be owned by the same user outside and inside the container.
An example of the attack is demonstrated in the screenshot below. On the left is the attacker with root within the container and on the right is the attacker without root on the host.
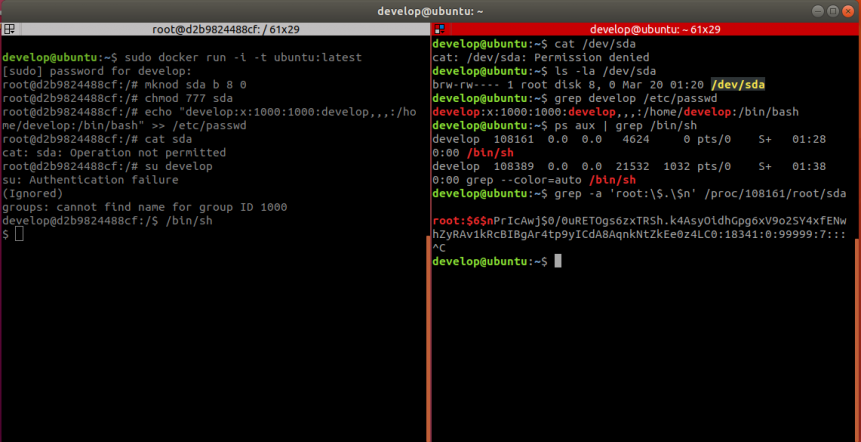
To show that the user develop now has full access to the filesystem we grab the root password hash from the /etc/shadow file.
This attack is easily prevented by following best practices by ensuring that nobody is root within the container and by running Docker with the parameter '–cap-drop=MKNOD'.
Enhancing symlink vulnerabilities
Another interesting abuse of the /proc/pid/root link into mount namespaces is that it can aid in the abuse of symlink vulnerabilities. To be clear about the extent of this issue we begin by describing user namespaces and their relation to mount namespaces.
A user namespace is a namespace that maps UIDs within the namespace to UIDs outside the namespace. The process creating the namespace decides this mapping. A common use of user namespaces is to map the UID 0 (root) inside of the container to a regular user outside of the container. This mapping is somewhat magic as for actions within the namespace the uid 0 is in fact root, but outside of the namespace the uid 0 is a regular user.
Part of the magic in using a user namespace combined with a mount namespace is that it allows a regular user to have control of the filesystem within their mount namespace through bind mounts.
For example, if they want to change their username within their namespace they cannot directly modify the /etc/passwd file, as doing so would require root permissions outside the namespace. However, they can use bind mounts to link an arbitrary files and folder to /etc.
Back to the vulnerability. To remove Debian packages the command 'apt remove <packagename>' is used. Some packages need to do additional cleanup when being removed, one of these packages has decided to clean out user configuration files by issuing the command ‘rm –rf /home/*/.config/programX’ as root.
This uninstall script has an obvious symlink vulnerability where a user can symlink their .config file to point to any directory and thus allow deletion of a file or folder named "programX" anywhere on the filesystem. While an issue in itself, such a vulnerability is hard to abuse as deletion of a file named programX is unlikely to cause much harm, especially as that program is being uninstalled.
Note that creating a symlink from /home/user/.config/programX to, for example, /etc/password will not work, as ‘rm’ will in that case only remove the symlink itself. The difference in behavior from when .config is symlinked is caused by the fact that programX is on the end of the path.
This is where the user and mount namespaces come in. Using user + mount namespaces, we can use a symlink on the .config folder to trick the script into our own mount namespace. Within our own mount namespace, we have control over the filesystem and can for example create a bind mount from the programX folder to /etc/. This bind mount is not a symlink and ‘rm’ will happily descend into the folder.
A demonstration of the attack is shown in the screenshot below. On the left is the simulated uninstall script with root privileges and on the right is the attacker without root on the host. The initial 'unshare –r –m' command creates a user and a mount namespace and enters it.
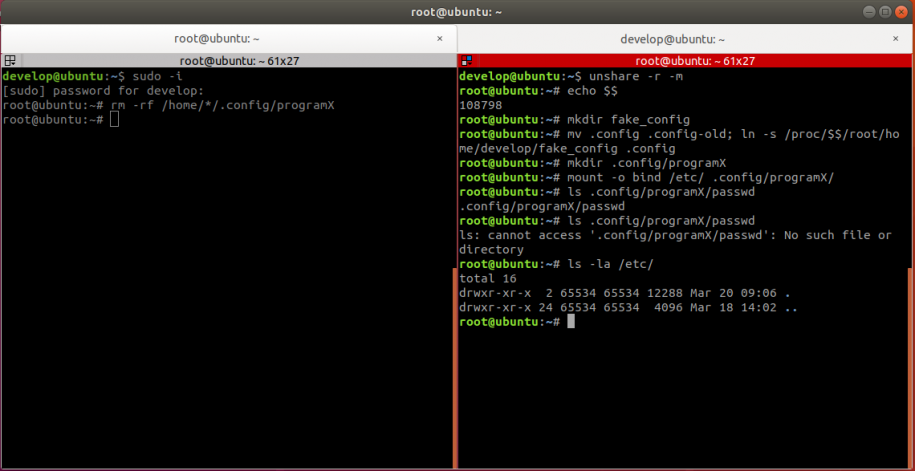
Note that the attacker needs to execute all commands before the first 'ls' command before the uninstall script is run, additionally the process and the namespace must be running on the system while the uninstall is taking place.
As this method is a way to increase the impact of symlink vulnerabilities, the suggested way of solving this issue is to fix symlink vulnerabilities. There are mitigations one can add, for example the 'rm -rf' command can be run through its own PID namespace, thus hiding access to the mount namespace through /proc/PID/root.
Conclusion
The use of containers is running ahead of publicly available research. Due to this, it is hard for developers to fully grasp the security implications of providing root access within a container and what implications addition of specific capabilities have on security.
Hopefully this blog post gave some insight into why it is bad to provide root within a Docker container and how namespaces can affect existing vulnerabilities.