MWR HackLab - Chubby Data
on 25 April, 2013
A small group of 6 sat down and had a look at the challenges you face when dealing with large amounts of data.
Luckily someone was kind enough to produce huge amounts of data just in time for HackLab. The data produced in this scan of the whole internet amounts to 9TB in raw files.
In preparation for HackLab we uploaded the compressed data to Amazon’s AWS infrastructure. Due to the compression algorithm that was used, decompression on a single desktop would take quite a while. In AWS however we were able to use a few cluster-compute spot-instances to go through this task rather quickly.
The idea of this project was to get a chance to play with new technologies that we aren’t exposed to on a daily basis. When trying to make this much data accessible you will run into problems with your traditional SQL databases or grep-fu. Our team split in smaller sub-teams to look at specific subsets of the data.
Search Engine for FTP Banners
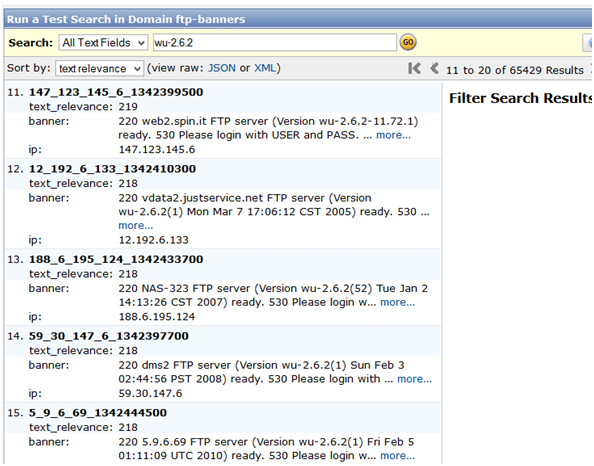
One part of the data was a scan of all FTP servers and the corresponding banner information retrieved from these servers. In total 12 million FTP servers were included in the scan, which we tried to make accessible for full text search. Several technologies exist for full-text search and we decided to take the lazy route by using Amazon Cloud Search, which scales automatically based on your data and volume of search queries. We wrote a basic parser in Python which uploaded the banner and IP information in JSON document format to Amazon Cloud Search. The parsing and upload only took a couple of hours and everything was done by the end of the day. Searching the data is convenient and very fast. We are currently working on a web interface which we can make available more widely. A screenshot of the full text search using Amazon’s interface can be seen below:
Interesting information from the NBTStat Scan
Another team split off to look at interesting information included in the scan of NBTStat exposed through UDP port 137. Most of the time was spent on implementing a sufficiently fast multithreaded parser for the responses contained in the raw data. As only half a million of these ports where exposed on the internet we were able to use a traditional SQL database to store the information. Included in this information we found a few interesting things, including a large amount of Windows domain controllers exposed on the internet. Expect a more detailed blog post on this in the future.
HTTP header data
Here at MWR we are happy to take any excuse to play with hipster NoSQL databases. We started by filling a CouchDB database with the header information from the GET scans of port 80. Our Python parser which bulk uploaded JSON documents into the database was surprisingly efficient (12 minutes for a class A network). Using MapReduce queries we were able to grab all kind of information from the available data, including statistics on the HTTP server distribution and outdated HTTP servers. We also started to build a full text search index over the database using Apache Lucene. Expect more on this in a future blog post.
In a competing approach we were playing with ElasticSearch for making the HTTP data available for full text search, which according to ElasticSearch’s website is not just cool, but bonsai cool!
The setup of ElasticSearch is incredibly easy and we were uploading our JSON documents in just a few minutes, which were then automatically indexed. ElasticSearch makes use of Apache Lucene and exposes very powerful search features. Searching the index on a comparatively low powered machine is almost instant. We are currently working on a web interface to make the HTTP header search available for everyone, the screenshot of our internal prototype can be seen below:

Conclusion
A lot of interesting information is hidden in the huge amount of data that was published by the Internet Census Project. Making this data accessible in a way which allows finding the interesting information in this data set is a huge task. This project is a great opportunity for us to play with technologies that we aren’t exposed to on a regular basis. We will be continuing to look at the data and will keep you updated on any progress.
If you have any ideas on what to do with the data or how to extend our current projects, please tweet at us at @mwrlabs.